

Le signe signifie, alors que la forme se signifie... Henri Focillon
Nous abordons dans ce chapitre la partie graphique de notre travail. Tout au long de notre étude, nos objectifs consistaient à reconnaître et à interpréter les signaux issus du stylo. Après avoir défini les domaines et les objectifs pour nos algorithmes de reconnaissance, nous les détaillerons en séparant la reconnaissance de l'interprétation. Nous verrons que les méthodes adoptées sont réutilisables dans les différents domaines abordés. Enfin, avant de fournir les résultats obtenus, nous nous intéresserons aux spécificités de la reconnaissance des formes dans le contexte de l'interaction Homme-Machine et plus spécifiquement à ce que nous appelons la production incrémentale.
La production de documents graphiques comporte plusieurs types d'activités tels que la création, la copie ou la correction, et une multitude de champs d'application, qui souvent se superposent, parmi lesquels nous citerons l'art, la technique, ou encore la géométrie.
De nombreuses études ont été menées sur des ordinateurs à stylo ou sur des tablettes dans différents domaines graphiques, et en particulier pour la reconnaissance de l'écriture. On trouvera dans [TAPP90] un état de l'art sur ce sujet. Ainsi, dès le début des années 80, on trouve des solutions, pour des diagrammes [LIN82] ou des dessins techniques [HARA85], permettant la reconnaissance hors-ligne. Puis le déferlement des ordinateurs à stylo ouvre une nouvelle voie de recherche qui aborde la reconnaissance des tracés graphiques dans un contexte d'interaction Homme-Machine, en ligne. Ainsi, [MURA86], [STOL93] et [APTE93] se sont intéressés à la reconnaissance de figures géométriques, [VRIE89] se penchant plus particulièrement sur les problèmes spécifiques à l'architecture. Des interfaces dédiées à ces applications ont été proposées par [PURC89], [BROC91], [ZHAO93] et [ZHAO93a], avec une attention particulière accordée aux gestes par [RUBI90]. Enfin, [WAKA92] s'est focalisé sur la reconnaissance de l'écriture.
Nous nous fixons comme objectif de développer la métaphore du papier en intégrant tous les types d'activités (création, copie, correction) dans un contexte de forte collaboration entre l'utilisateur et la machine. Cette intégration implique la définition et l'élaboration d'un métalangage provenant du stylo. En effet, il est indispensable de distinguer les données des commandes produites à l'aide de ce seul médium. Nous considérerons que le métalangage est constitué par l'ensemble des tracés de gestes 2D qui seront traités par des algorithmes spécifiques.
En ce qui concerne les données graphiques, nous étudierons la production en ligne de tableaux qui n'a fait à ce jour, à notre connaissance, l'objet d'aucune étude. De plus ceux-ci peuvent présenter des singularités qui seront très intéressantes à reconnaître et à interpréter: symétries, alignements, etc...
Dans un second temps nous développerons des méthodes et des algorithmes plus généraux en vue de reconnaître des productions graphiques de domaines moins contraints que les tableaux mais où les singularités graphiques sont aussi très présentes. Dans ce contexte, l'étude des diagrammes en réseau nous servira de support et de test.
Comme nous l'avons déjà signalé, nous séparerons cette partie en deux: la reconnaissance au niveau du signal d'une part et l'interprétation d'un dessin, qui est la recherche d'une sémantique au niveau cognitif, d'autre part.
Le signal issu d'un stylo, quel qu'il soit, est au moins composé de suites de coordonnées qui représentent les points de la trace du stylo entre les posers et les levers successifs. C'est le traitement bas niveau de ces données brutes que nous exposons dans cette partie.
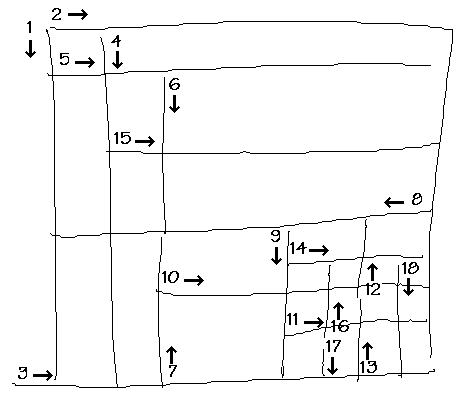
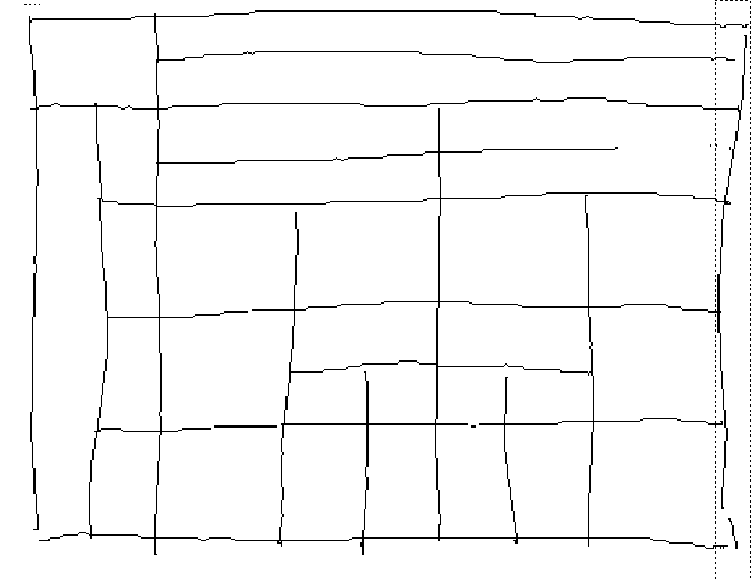
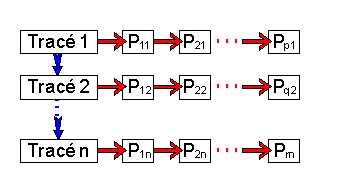
Nous présentons ici la reconnaissance automatique des tableaux qui est mise en œuvre dans le programme TAPAGE [JULI94]. Afin de bien comprendre comment fonctionne ce module de reconnaissance, il est présenté en 6 étapes. Nous détaillerons chacune d'entre elles. Considérons tout d'abord un dessin simple où nous avons rajouté le sens des tracés (Figure 20).
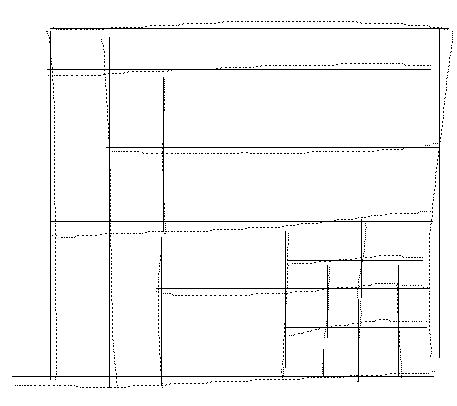
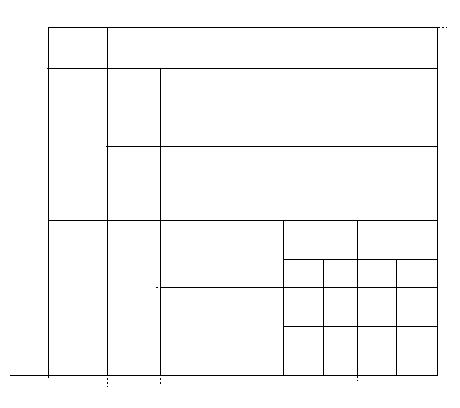
Dans chacune des 6 figures suivantes nous rappellerons en pointillés l'allure du tableau avant chaque étape de la remise en forme pour bien se rendre compte des changements intervenus. La première étape de la remise en forme automatique dans TAPAGE (Figure 21) consiste à polygonaliser chaque tracé en n'autorisant que des segments verticaux (V) et horizontaux (H). La suite des segments de la ligne polygonale est obtenue par comparaison des abscisses et ordonnées d'un ensemble de points repères du tracé. Cette opération utilise un seuil fixé a priori, qui a été déterminé en fonction de la résolution de l'écran. L'algorithme de polygonalisation fonctionne par dichotomie récursive, il est assimilable à un algorithme de la corde ou à l'étape split d'une méthode split and merge [PAVL77]. Pour chaque tracé, le critère d'alignement de points repères est évalué. Les points repères d'un tracé de longueur L sont situés aux positions : 0, L/4, L/2, 3L/4, L. Quand ce critère n'est pas vérifié (c'est le cas du tracé n° 2), le tracé est découpé en deux au niveau du point repère L/2 et l'algorithme est appliqué sur les tracés résultants. La Figure 21 montre les segments H et V obtenus après cette étape, l'allure du tableau original est rappelée en pointillé. Le choix de points repères pré-définis rend l'algorithme de la corde sous-optimal mais évite de calculer les distances à la droite d'approximation pour chaque point et par suite permet un gain de temps. Ce choix n'affecte pas de manière visible les performances de la segmentation en V et H. De plus, les informations relatives aux sens des tracés sont perdues intentionnellement afin d'uniformiser la notion de verticale (segment allant de haut en bas) et celle d'horizontale (segment allant de gauche à droite), ce qui permet d'utiliser une structure de données plus légère dans les étapes suivantes.
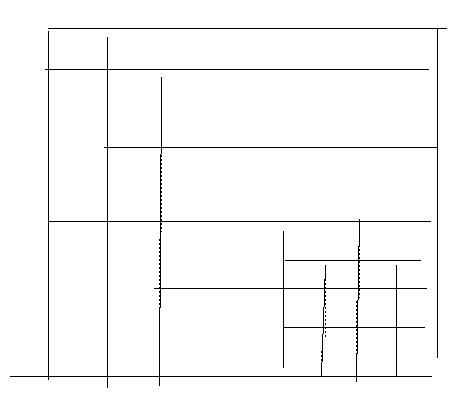
Lors de la seconde étape (Figure 22) il y a recherche d'alignements des segments construits à l'étape un, c'est le merge de la méthode split and merge. Les segments obtenus ne sont pas forcément verticaux ou horizontaux, c'est l'étape trois (Figure 23) qui va les redresser. C'est au cours des étapes deux et trois que l'on va commencer à maintenir des listes de coordonnées correspondant à des grilles d'aimantation définies localement.
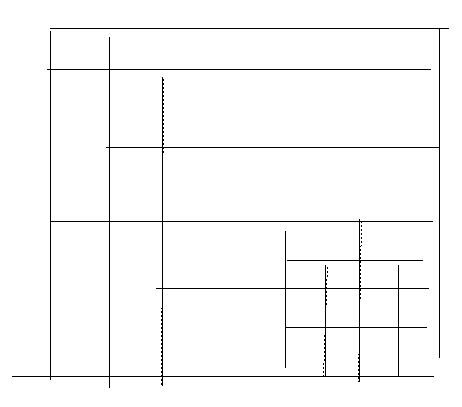
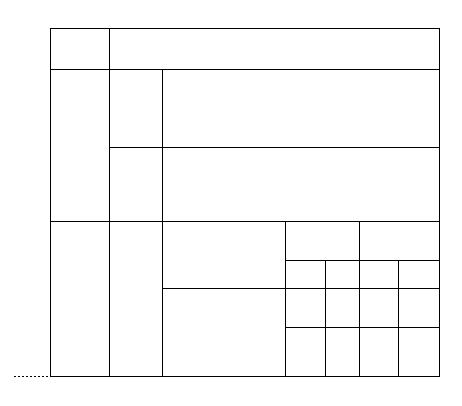
Une grille d'aimantation (Figure 24) englobe chaque tracé interprété H ou V. Sa taille est calculée pour chacun des tracés en fonction de la dispersion des points initiaux du tracé brouillon autour du segment H ou V reconstruit par l'algorithme de segmentation. Plus la dispersion de ces points est grande (plus le dessin est brouillon) plus la taille de la grille sera importante. Cette grille définie des seuils locaux qui seront utilisés pour la suite de l'interprétation. Comme on le voit sur la Figure 25, la quatrième étape de correction automatique permet d'éliminer les petits dépassements et de remplir les espaces au niveau des jonctions en T ou en L. Les coordonnées des segments V et H reconstruits aux étapes précédentes, associées aux tailles des grilles d'aimantation locales, vont permettre la détermination des références (notées Ref) et la reconstruction des jonctions T et L.
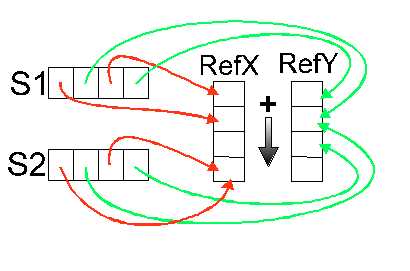
Algorithme de recherche des références :
- Soit X1, la première abscisse traitée, alors RefX1=X1 est la première référence pour les abscisses.
- Soient Xi une autre abscisse et j le nombre de références d'abscisses définies à cet instant.
- Si Xi RefXk avec k[1,j] et signifie "est proche de" et utilise les seuils locaux définis à partir des grilles d'aimantation.
Alors RefXk =(RefXk +Xi)/2
Sinon RefXj+1=Xi est une nouvelle référence pour les abscisses.
De même pour les ordonnées.
Tous les segments sont alors définis grâce à ces références. L'effet d'aimantation est une égalisation de la valeur des abscisses (respectivement ordonnées) des points qui sont à l'intérieur d'une même grille d'aimantation définie pour un segment V (respectivement H). La conséquence sera une reconstruction de la plupart des jonctions T et L, comme on peut le constater sur la Figure 25.
L'étape précédente a éliminé la plupart des extrémités libres des segments uniquement par un choix de structure de données, il peut toutefois en rester d'autres, le seuil d'aimantation s'avérant trop faible. La cinquième étape (Figure 26) se divise en deux parties : la recherche d'une extrémité libre puis la détermination du segment perpendiculaire le plus proche pour effectuer une connexion en T ou en L. Ces opérations sont particulièrement lourdes en temps de calcul (surtout la seconde). L'intérêt de l'étape 4 est très visible en comparant les Figure 25 et Figure 26: il ne reste à l'étape 5 qu'une seule jonction en L à traiter (jonction L en bas à gauche) alors que l'étape 4 a déjà traité 21 jonctions T ou L.
La remise en forme du tableau est terminée. Le traitement sémantique de celui-ci sera décrit plus loin.
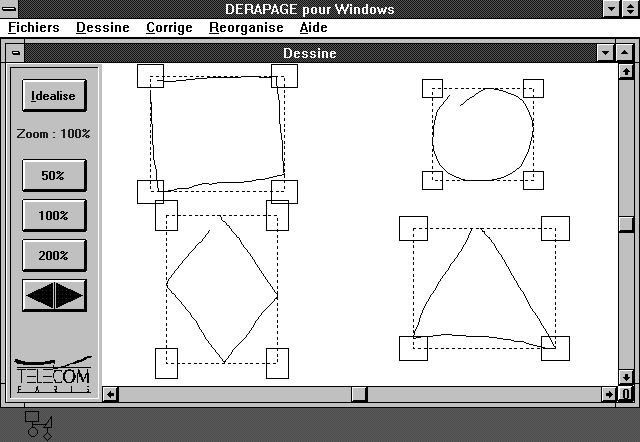
Pour la reconnaissance des diagrammes, nous avons eu l'idée de mettre en œuvre deux méthodes de reconnaissance: la reconnaissance tardive et la reconnaissance à la volée. La reconnaissance tardive est une adaptation de l'algorithme de TAPAGE, utilisant des méthodes analytiques pour transformer le dessin en une suite de segments. La reconnaissance à la volée a été développée pour alléger le travail de la reconnaissance tardive et ne s'applique qu'à un certain type de données.
La reconnaissance tardive
Dans TAPAGE, l'algorithme de remise en forme se limitait aux horizontales et aux verticales d'un tableau. Afin de généraliser la méthode, nous avons ajouté dans la reconnaissance tardive les lignes obliques. Les données (Figure 27, fenêtre de droite) sont traitées en deux étapes. La première est une segmentation qui transforme les tracés en segments par la méthode de dichotomie récursive décrite plus haut. La seconde rassemble les segments contigus qui ont à peu près la même direction. Il ne s'agit plus ici de verticales et d'horizontales mais de N directions principales, N variant en général de 8 à 16. Chaque segment résultant devient alors un objet graphique autour duquel on définit une zone d'aimantation qui dépend de la taille du rectangle englobant du tracé initial. La Figure 28 montre que la taille de ces zones d'aimantation dépendent de la qualité du dessin brouillon. La taille des zones définit les valeurs des seuils locaux pour attirer les extrémités libres des segments et reconstruire la majorité des jonctions. A ce stade de l'algorithme, la variabilité de la qualité du dessin a été atténuée par l'extraction des références. Le dessin est propre, mais les figures ne sont pas encore détectées. Afin de découvrir les figures dans le dessin, on donne une description structurelle de chacun des éléments recherchés. Le modèle de l'objet est donc une organisation de segments qui correspond à sa description géométrique. Ainsi un rectangle est composé de quatre segments ((Xa1,Ya1)-(Xa2,Ya2), (Xb1,Yb1)-(Xb2,Yb2), (Xc1,Yc1)-(Xc2,Yc2), (Xd1,Yd1)-(Xd2,Yd2)) qui doivent vérifier les égalités:
Xa1= Xd1, Xa2= Xb1, Xb2= Xc2, Xc1= Xd2, Ya1= Yd1, Ya2= Yb1, Yb2= Yc2, Yc1= Yd2
et Xa1= Xc1, Xa2= Xc2, Ya1= Yb1, Yd2= Yb2.
Une description similaire est donnée pour chaque figure (Rectangles et Triangles dans DERAPAGE). Il est facile d'en rajouter d'autres (trapèze, parallélogramme, etc...) en en donnant les descriptions appropriées.
La reconnaissance à la volée
Cet algorithme est appelé "à la volée" parce qu'il est utilisé dans DERAPAGE [JULI95b] pour traiter certaines données avant d'invoquer la reconnaissance tardive qui est mis en œuvre des mécanismes plus lourds et plus lents. Comme nous le verrons, c'est aussi cet algorithme que nous utilisons pour reconnaître les gestes produits lors des phases d'édition.
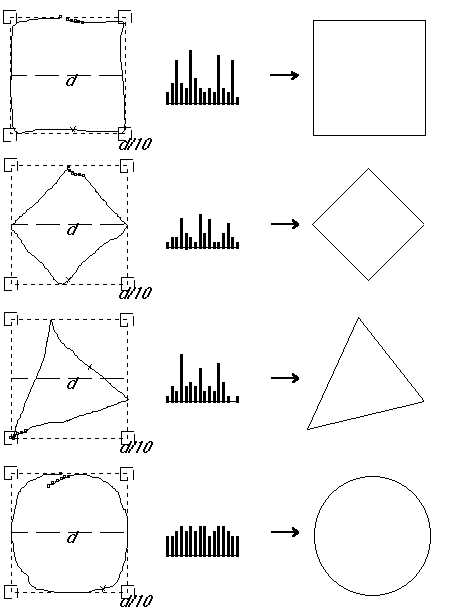
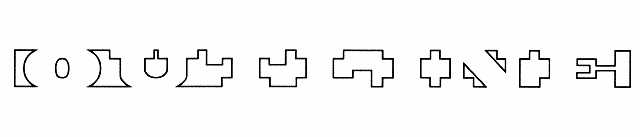
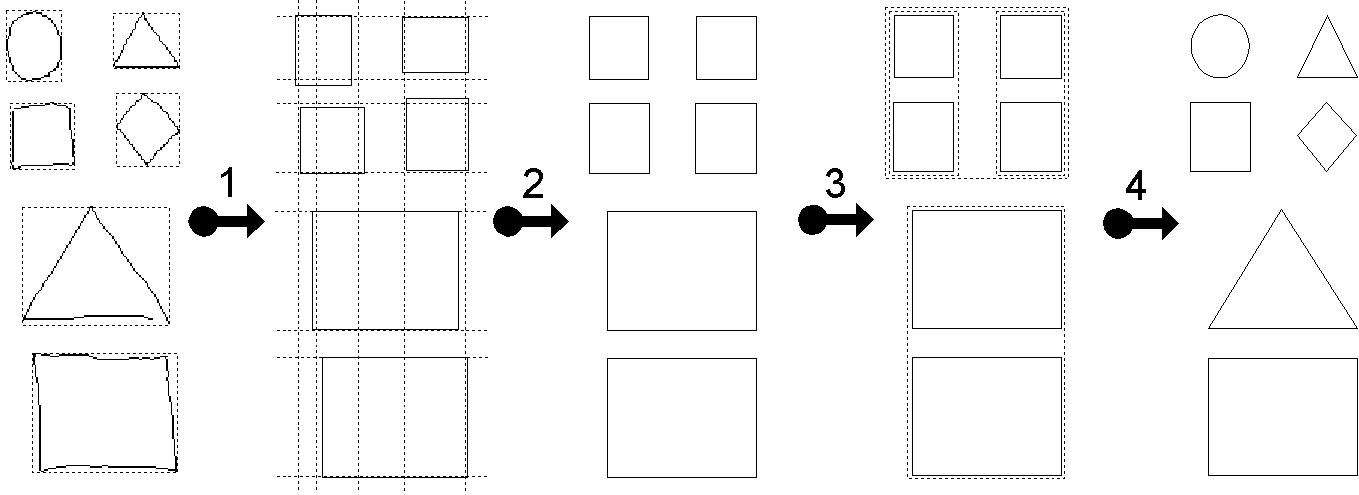
Le but de cet algorithme est de reconnaître un ensemble de figures produit par l'utilisateur. Une figure est une suite de tracés, chaque tracé est une suite de points dont on connaît les coordonnées. Chaque tracé est traité séparément et est défini par un ensemble de caractéristiques: nombre et valeurs de ses directions principales, rectangle englobant et ce que nous appelons ses coins sensibles. Nous avons déterminé ces caractéristiques en nous inspirant très librement d'un travail de neurosciences sur la vision d'animaux [HUBE87], où le champ de vision est présenté comme une juxtaposition de zones. Les directions principales sont calculées suivant la méthode de Freeman sur 8 ou 16 directions [ROSS93] en fonction de la qualité de reconnaissance nécessaire et suffisante: il est en effet inutile d'engager le processus de calcul sur 16 directions si l'application ne doit reconnaître qu'un nombre limité de figures. Ce choix est arbitraire. Les coins sensibles sont des rectangles à chaque coin du rectangle englobant qui ont une taille proportionnelle à celui-ci (Figure 29). Après le calcul des caractéristiques des tracés, on effectue un appariement au modèle (model matching) sachant que chaque modèle est représenté par une description du tracé ou par une suite de description du tracé.
Pour utiliser la reconnaissance à la volée, nous avons dû choisir un type de tracés qui serait pris en charge par cet algorithme. Nous avons pensé lui envoyer toutes les courbes fermées. C'est un partage des tâches empirique mais qui s'est avéré efficace dans un contexte d'interaction Homme-Machine où le temps de réaction de la machine doit être le plus petit possible. Nous choisissons donc les courbes fermées, formées d'un seul tracé continu. Nous définissons une courbe fermée comme étant une suite de points dont au moins un des points du dernier quart du tracé a des coordonnées proches du premier point du tracé. Les principales étapes des calculs que nous effectuons sur ce tracé sont:
La Figure 30 nous montre un exemple de quantification vectorielle sur 16 directions, avec des CS dix fois plus petits que le resctangle englobant. La variation empirique de ces paramètres permet de jouer sur la qualité de la reconnaissance en fonction des objets à reconnaître. Dans cet exemple, les descriptions des figures sont:
A ce moment, les figures sont reconnues. Les tracés ayant été pris en charge par la reconnaissance à la volée sont retirés de la liste de tracés qui sont envoyés à la reconnaissance tardive. Si des tracés n'ont engendré aucune décision, ils restent dans la liste.
Un exemple complet, avec reconnaissance des liens
Que ce soit par la reconnaissance à la volée, ou la reconnaissance tardive, quand un objet est reconnu, on enlève de la liste des tracés les éléments qui le composent et on ajoute l'objet dans une nouvelle liste, celle des englobants. Cette liste contient le type de l'objet et ses dimensions et sera d'un grand intérêt pour l'interprétation structurelle.
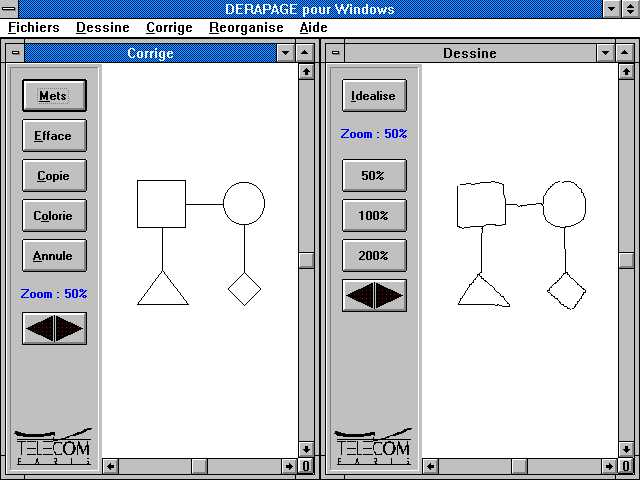
Dans le cas spécifique de DERAPAGE, où on cherche à reconnaître des diagrammes en réseau, les liens n'ont pas été reconnus par la reconnaissance à la volée et n'ont pas été intégrés dans des figures lors de la reconnaissance tardive. Ce sont des segments libres qui ont été lissés mais qui restent dans la liste des segments à traiter. La Figure 31 en montre un exemple: le cercle et le losange ont été trouvés par la reconnaissance à la volée. Le rectangle, dessiné en plusieurs fois, a lui été reconstruit dans la reconnaissance tardive. Enfin les segments libres restants sont considérés comme des liens. On voit qu'à chaque étape, les tracés qui forment une figure reconnue sont retirés de la liste des éléments à traiter.
On donne ici une limitation de la méthode. Si un cercle ou une ellipse sont dessinés à l'aide de plusieurs tracés, ils ne seront pas reconnus. En effet, dans notre exemple, seule la reconnaissance à la volée est susceptible de reconnaître les ellipses. Pour que la reconnaissance tardive puisse le faire il faudrait donner la description d'une ellipse à l'aide d'une relation entre segments, ce que nous n'avons pas fait, le nombre de directions étant insuffisant.
Nous avons remarqué plus haut que l'algorithme à la volée est aussi utilisé pour reconnaître les gestes de nos applications (Figure 32). Si l'algorithme principal est strictement le même, il est utilisé avec les gestes d'une façon un peu différente, qui permet une meilleure utilisation de ses capacités.
Dans le cas des diagrammes, la reconnaissance à la volée est utilisée pour suppléer de façon efficace la reconnaissance analytique. Pour les gestes, cet algorithme est utilisé seul. En effet, quand l'utilisateur dessine, il ne faut pas que la machine soit trop intrusive (on trouvera une argumentation dans [NAKA93]), elle doit le laisser terminer son dessin, c'est lui qui décidera quand elle peut débuter son interprétation. Au contraire, le geste est une commande en soi, dans notre approche, il ne doit pas être validé. La machine doit commencer son interprétation durant la production pour fournir une réponse le plus rapidement possible. Dans certains cas, lorsque le contexte de création n'est pas explicitement donné par l'utilisateur, nous mettons cet algorithme de reconnaissance des gestes en compétition avec un algorithme de reconnaissance de l'écriture, la rapidité d'exécution et d'interprétation est cruciale pour ne pas ralentir le processus global de l'interaction.
La Figure 32 montre un ensemble de gestes utiles pour la correction lors de la production graphique (déplacement, effacement, sélection). La première différence que l'on remarque avec l'algorithme utilisé pour la reconnaissance des diagrammes est que les objets peuvent comporter plusieurs tracés et ne sont pas forcement fermés. En effet, ici, ces restrictions sont inutiles puisque c'est le seul algorithme de reconnaissance d'objets graphiques mis en œuvre. Ceci permet de concevoir vocabulaire de gestes, où la seule limitation est d'avoir des valeurs assez discriminantes sur les caractéristiques que nous utilisons. Dans cet exemple, le modèle de la rature est un tracé comportant au moins 2 directions principales, le modèle de la flèche est composé de deux tracés: le premier avec une direction principale, le second en a deux. Dans ce cas les positions relatives des rectangles englobants les tracés vont donner le sens de la flèche et le rectangle englobant du premier tracé donnera la position des objets concernés par le geste et la destination de ceux-ci. Comme on le voit, nous mettons à profit les éléments qui permettent de reconnaître l'objet graphique pour obtenir les informations liées à la commande générée.
Nous donnons ici un exemple de distribution suffisamment discriminante de gestes sur des caractéristiques que nous utilisons dans PAVE [JULI95a]:
Extrémités proches (1=oui, 0=non) 1 1 0 0 0
Nombre de directions (1=5à16,0=1à4) 1 1 1 1 0
Cassure nette (1=oui, 0=non) 1 0 1 0 0
Si nous avons déjà vu les caractéristiques Extrémités proches et Nombre de directions, nous en présentons ici une troisième qui tend à prouver qu'il est facile de trouver des caractéristiques originales en utilisant seulement les données de base. La Cassure nette se calcule entre deux directions successives. Si la direction est opposée, ou proche de l'opposée, il y a une cassure nette. Nous remarquons qu'il aurait été impossible de différencier la rature de l'encerclement sans la caractéristique Cassure nette.
Pour toutes nos applications, les données issues du stylo sont enregistrées sous la forme d'une liste de tracés, chaque tracé étant lui-même formé d'une liste de coordonnées des points qui le composent (Figure 33). En réalité, les données ainsi représentées ne sont pas tout à fait brutes. Un prétraitement est effectué à la source afin d'éliminer les répétitions de points, ceci permet d'utiliser la structure quelle que soit la vitesse d'échantillonnage du digitaliseur utilisé. L'information que nous décidons de perdre, l'accumulation, n'est pas utilisée dans nos algorithmes et est même nuisible à leur bon fonctionnement lors de la dichotomie récursive.
Notre objectif est d'obtenir à partir des listes de listes de points une représentation vectorielle des dessins produits. Pour illustrer les solutions adoptées, nous reprenons la séquence de reconnaissance sur le tableau donné en exemple (Figures 20 à 26) et nous détaillons l'évolution des représentations internes successives. Nous rappelons que dans ce cas, nous ne nous intéressons qu'aux segments verticaux et horizontaux:
Tableau de 18 listes de ni points chacune où un
Tableau original point est un couple (X,Y) d'entiers et 1i18.
Tableau de 19 puis 16 segments où un segment
Etapes 1 et 2 est un quadruplet (X1,Y1,X2,Y2) avec X1X2 ou/et
Y1Y2.
Tableau de 16 segments où un segment est un
Etape 3 quadruplet (0,Y,X1,X2) si horizontal et
(1,X,Y1,Y2) si vertical avec X1X2 et Y1Y2.
Tableau de segments où un segment est un
Etapes suivantes quadruplet (0,RefYk,RefXi,RefXj) ou
(1,RefXl,RefYm,RefYn) avec RefXi ou RefYk les
rangs dans une grille d'aimantation.
Les raisons de ces choix de représentation interne pour les tableaux :
Les données sont directement récupérées à partir du stylo, il y a donc création naturelle d'une liste de points consécutifs. On s'attache à supprimer les points redondants à la source. Un poser de stylo correspond à la création d'une nouvelle liste.
Intérêt : On connaît facilement le nombre de tracés.
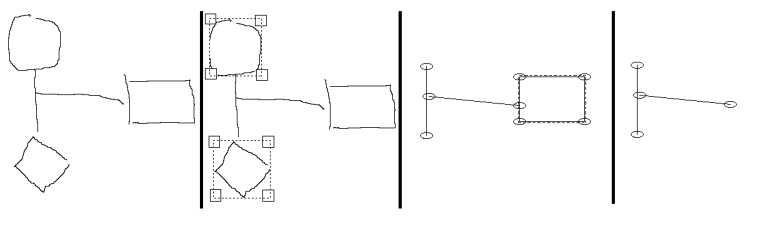
Pour cette partie de la correction automatique, les segments obtenus sont quelconques. Nous adoptons donc la représentation classique d'un segment par les coordonnées (X1,Y1,X2,Y2) de ses extrémités. Nous effectuons toutefois d'éventuelles modifications en donnant un sens conventionnel aux segments : ils vont de haut en bas et de la gauche vers la droite, de manière à ce que X1X2 ou/et Y1Y2, nous introduisons ici une notion de segment "plutôt vertical" ou "plutôt horizontal".
Intérêt : Uniformisation de la représentation d'un segment : pour savoir si deux segments peuvent n'en former qu'un, un seul test de proximité des extrémités au point de recollement est nécessaire, et non pas quatre (Figure 34).
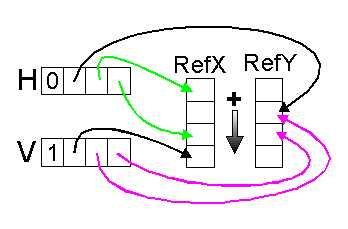
C'est à partir de ce moment que l'on est sûr de n'avoir que des verticales ou des horizontales. Chaque segment est représenté par un entier indiquant sa classe de direction, H (0) ou V (1), et des pointeurs sur des listes de références qui spécifient la position du segment (pointage sur une référence X, respectivement Y, pour un segment V, respectivement H) et des points extrémités. Par exemple, quand un segment H est en contact avec deux segments V à chacune de ses extrémités, ce qui est toujours vrai dans le cas des tableaux à cellules fermées, les références X pointées par H sont aussi les références de position de ces segments V. Tout est trié dans un ordre croissant comme précédemment.
Intérêt : Coder le type de segment dans le premier élément du quadruplet est très intéressant pour la recherche des connections en T ou en L: on ne comparera que les segments perpendiculaires.
Les segments étant alors horizontaux ou verticaux, nous allons garder la même représentation globale que ci-dessus mais nous introduisons les zones d'attractions (ou grilles d'aimantation). On crée alors deux nouvelles tables de références, une pour les abscisses et une pour les ordonnées, les rangs de ces tables apparaîtront désormais à la place des coordonnées réelles dans le tableau de segments (Figure 35). Pour l'optimisation des traitements futurs, les références sont triées dans l'ordre croissant.
Intérêt : Pratiquement toutes les connexions en L ou en T se font automatiquement. On introduit ainsi une notion de seuil local. Facilite la propagation lors d'un changement de coordonées d'un segment.
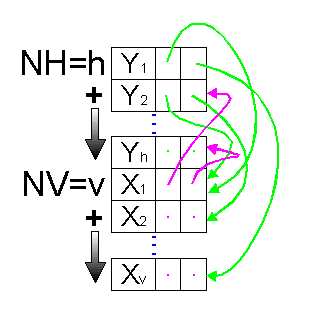
Dans un second temps, nous avons tenté d'améliorer encore cette structure de données en l'allégeant et en multipliant les références croisées. Nous sommes partis de la constatation que les grilles d'aimantation, et donc les tables de références contenaient au cours du traitement les coordonnées réelles du tableau final. Nous avons donc eu juste l'idée de fusionner les tables de références avec la liste représentant les segments. Ainsi la structure finale se limite à une seule liste triée, qui comporte dans sa première partie les NH horizontales et dans sa seconde les NV verticales (Figure 36).
Pour les algorithmes n'utilisant pas uniquement des horizontales et des verticales (cas des diagrammes en réseau), nous avons choisi une représentation proche, mais il était impossible de faire le même genre d'optimisation (Figure 37).
Cette organisation des données permet de propager rapidement des modifications locales dans l'ensemble du dessin par simple changement d'une valeur de référence et héritage de cette valeur pour les segments qui pointent sur elle.
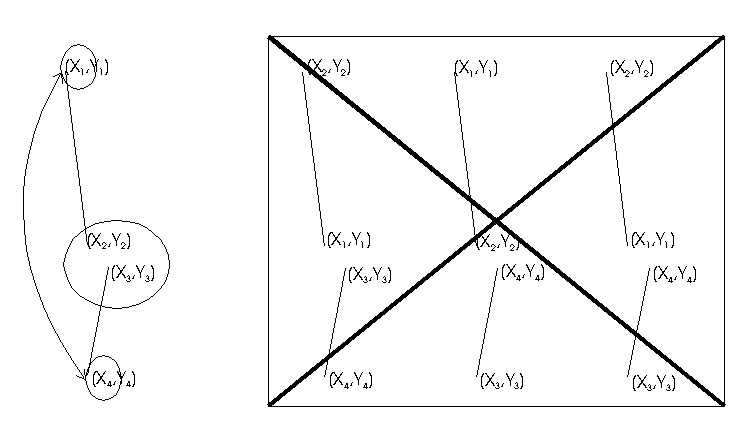
Après les étapes de redressement, les tableaux ou les diagrammes ont une allure correcte, ils n'ont toutefois pas encore la structure exacte que souhaitaient leur donner les concepteurs : certaines différences de tailles entre des lignes et des colonnes ou des alignements ne sont pas significatifs; ils résultent de l'imprécision introduite par la production manuscrite. Une analyse sémantique du dessin obtenu est nécessaire pour éliminer ces différences. En effet, toute différence (de taille, de forme, de position...) produit forcément chez le lecteur des tentatives d'interprétations [BERT77], [MARK90] et toute mauvaise présentation peut conduire à des problèmes d'interprétations (Figure 38 et Figure 39). Il s'agit ici d'exemples de perceptions bas niveau, qui, dans le domaine de la sémiotique graphique, mettent bien en évidence les problèmes d'interprétation sur lesquels nous voulons insister.
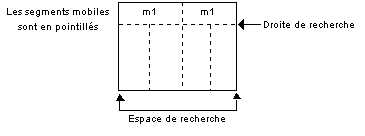
Cette correction sémantique est faite dynamiquement par un algorithme récursif. On introduit tout d'abord la notion de segment fixe et de segment mobile. Au départ seuls les segments les plus à l'extérieur (c'est-à-dire le cadre du tableau) sont fixes. Cette notion est nécessaire pour la recherche de motifs qui permettent la remise en forme finale du tableau.
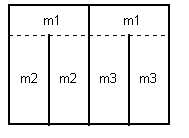
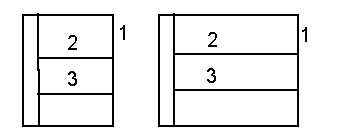
Un motif est défini comme une zone entre deux segments horizontaux et verticaux successifs (Figure 40), il est caractérisé par sa largeur s'il s'agit d'un motif horizontal (dans l'exemple détaillé ici, ce sont des motifs horizontaux qui sont recherchés) et par sa hauteur pour un motif vertical. Les motifs horizontaux sont d'abord recherchés, puis les motifs verticaux. Les motifs horizontaux (verticaux) sont recherchés entre deux verticales (horizontales) successives fixes qui forment l'espace de recherche le long d'une horizontale (verticale) qui constitue la droite de recherche (Figure 41). L'ordre de recherche est fixé d'une part par les positions des segments dans le tableau, de gauche à droite pour les horizontaux, de haut en bas pour les verticaux, et d'autre part dynamiquement à mesure que les segments sont fixés.
Cette dynamique implique un algorithme récursif. Deux motifs sont "identiques" quand les grandeurs qui les caractérisent (largeur ou hauteur) sont égales, à la tolérance près du seuil d'égalisation. La remise en forme fixe les segments mobiles qui délimitent les suites de motifs "identiques" dans des positions où l'égalité des grandeurs est stricte.
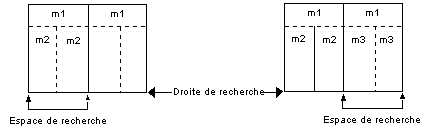
On note sur la Figure 42 que l'identité des motifs m2 et m3 résulte d'un héritage de propriétés et non d'une connaissance explicitement représentée dans la structure de données. C'est parce que le motif m1 a permis de séparer le tableau en deux parties égales que m2 et m3 se retrouvent être identiques. L'algorithme exploite des propriétés structurelles pour limiter son calcul d'identité de motif à ce qui est strictement nécessaire.
Si l'on reprend l'exemple donné pour la reconnaissance des tableaux, les Figures 43a et 43b nous donnent le résultat de l'interprétation. Le tableau définitif est affiché sur l'écran, moins d'une demi-seconde après la fin de la saisie du dessin.
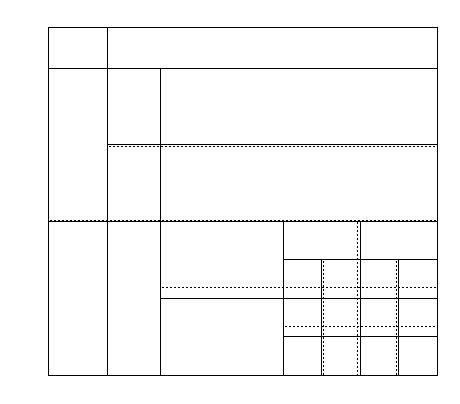
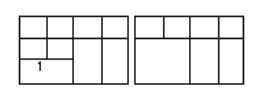
La technique utilisée dans TAPAGE a été là encore étendue pour trouver les structures globales des dessins créés dans DERAPAGE. La Figure 44 illustre les étapes de la méthode. Durant la reconnaissance des figures décrites plus haut, une liste des englobants est créée et mise à jour. Dans un premier temps (étape 1), il y a création d'une nouvelle grille magnétique par recherche de références, moins fine que celle utilisée dans l'algorithme de reconnaissance tardive. Nous nous permettons une reconnaissance moins fine car il ne s'agit plus de reconnaissance d'objets locaux, mais de reconnaissance de structures globales. Cette nouvelle grille permet de décrire chaque englobant avec de nouvelles références (étape 2).
La troisième étape de l'algorithme est une comparaison récursive entre englobants. Chaque fois qu'au moins deux englobants voisins sont similaires par leur forme et leur taille, un nouvel englobant les entourant est créé. Cette opération continue jusqu'à ce qu'une nouvelle construction d'englobant soit impossible. Le résultat d'un tel algorithme est que tous les objets appartenant à un englobant sont identiques en fonction du niveau de recursion. La dernière étape consiste en la redéfinition de chaque objet entouré avec ses nouvelles dimensions.
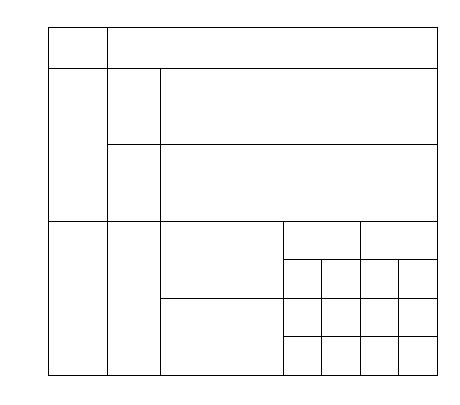
Comme on le voit à gauche de la Figure 45, des englobants croisés multiples peuvent être trouvés au même niveau de recursion avec cette méthode. Il serait possible de décider que chaque objet n'appartient qu'à un seul englobant (cela pourrait être le premier trouvé comme en Figure 44) mais des alignements significatifs pourraient être perdus dans cette opération. Une autre solution est d'assigner une valeur de contrainte à chaque englobant correspondante au nombre d'objets englobés. Dans l'exemple ci-dessus (Figure 45), les englobants A et B seront liés afin de conserver les deux alignements, même si un nouveau niveau de récursion change la taille de A à cause de C (Figure 45 à droite). Après cela, les objets inclus dans B auront la même allure que ceux inclus dans A car A a une valeur de contrainte plus grande que B. Nous introduisons à ce stade une nouvelle contrainte qui sera propagée durant tous les calculs. C'est une contrainte de régularité d'une figure: si un englobant est presque un carré, l'objet reconstruit à partir de cet englobant sera régulier, c'est à dire qu'un objet ellipse contenu dans un tel englobant forcera la reconstruction d'un cercle parfait. Cette contrainte prend une valeur maximale.
Pour le cas des diagrammes en réseau, une amélioration de la présentation du dessin final est apportée par un choix empirique plutôt qu'un choix sémantique: si des segments libres ont été trouvés et rattachés à des englobants, ils sont automatiquement collés sur les milieux des côtés de ces englobants (Figure 46).
La résolution des surfaces réactives des ordinateurs à stylo est assez grossière, de l'ordre de 30 points par cm, et la parallaxe rend difficile une localisation exacte du stylo sur l'écran. En l'absence de l'égalisation automatique, qui correspond à l'interprétation de structure, il serait impossible d'obtenir des lignes et des colonnes égales pour des tableaux ou des diagrammes parfaitement alignés. En revanche, si le dessinateur désire créer intentionnellement des lignes ou des colonnes adjacentes de taille légèrement différentes, il verra le système égaliser à chaque interprétation. La séparation entre le module d'interprétation des données et celui de l'interprétation des structures peut être exploitée pour empêcher des égalisations et permettre des différences minimes entre tailles de motifs en désactivant ce dernier module à la demande de l'utilisateur.
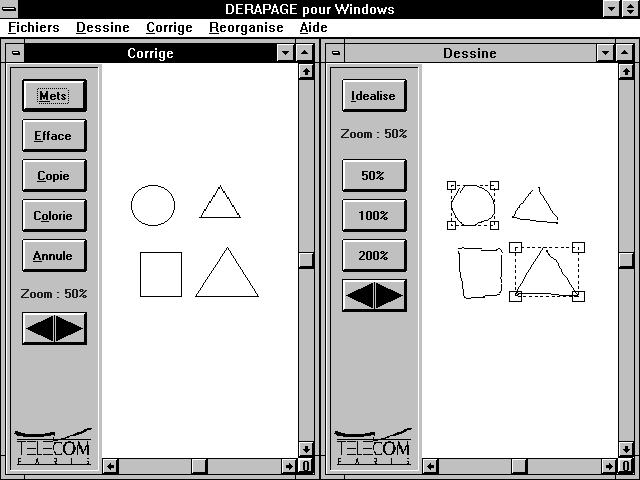
Pour comprendre les problèmes rencontrés pour la réalisation d'un éditeur de dessins interactif, nous donnons le scénario d'une interaction entre un utilisateur et la machine: un dessin est produit au stylo sur l'écran de l'ordinateur et immédiatement interprété par la machine, la version idéalisée est retournée. Cette version peut ne pas satisfaire l'utilisateur, soit parce qu'une erreur d'interprétation a été faite, soit parce que l'utilisateur a produit un dessin qui ne correspond pas exactement à ses intentions qui évoluent au cours de la conception incrémentale. L'utilisateur a alors la possibilité de corriger son tableau à l'aide d'outils disponibles au niveau de l'interface, les modifications apportées sont interprétées et le dessin mis à jour est affiché instantanément. Comme nous l'avons vu, l'interprétation fait intervenir des procédures de traitement et de reconnaissance des données saisies en ligne ainsi que des connaissances liées au domaine d'application. Dans un contexte de coopération Homme-Machine, l'interprétation de dessins est soumise à plusieurs contraintes.
La première contrainte est celle du style de production dont la qualité est très variable d'un dessinateur à l'autre et même à l'intérieur d'un même dessin. Cette qualité semble liée à la vitesse d'exécution du dessin. Les seuils de tolérance qui sont forcément impliqués dans les décisions de l'interpréteur ne doivent pas être figés, d'où notre solution de créer des grilles d'aimantation qui permettent des adaptations locales à la qualité du dessin.
La seconde contrainte est caractéristique d'une situation d'interaction utilisateur-machine, c'est la contrainte de temps : que ce soit lors de la création, ou lors des modifications, l'interprétation doit être immédiate, les structures de représentation et les calculs ont été optimisés dans ce but. La négociation entre la qualité et le temps de l'interprétation ont été menée au plus juste, avec deux impératifs : l'utilisateur ne doit pas attendre plus d'une seconde un résultat et le résultat obtenu ne doit pas être aberrant pour l'utilisateur.
Il faut ajouter à cela la contrainte de coopération, sans doute une des principales caractéristiques de la production incrémentale, qui impose un partage des tâches entre machine et dessinateur lors de la modification du dessin. La machine doit propager automatiquement des modifications locales dans la structure du dessin et effectuer les modifications qui sont suggérées par celles de l'utilisateur pour maintenir une cohérence globale du dessin.
Une interprétation totale des dessins est effectuée à chaque étape de la conception incrémentale. L'utilisateur peut faire évoluer son dessin par des modifications: il peut ajouter, déplacer, dupliquer ou effacer des composantes graphiques. La structure du dessin est définie en fonction de la tâche. Elle doit être conservée quand l'utilisateur provoque des modifications locales. Le système prend alors en charge la mise à jour du dessin et reconstruit une structure valide en tenant compte de la structure préexistante et des changements apportés. Il y a donc partage de la tâche entre l'utilisateur et la machine qui propage la modification locale provoquée par l'utilisateur à l'ensemble du dessin en réalisant des modifications supplémentaires que l'utilisateur n'a pas besoin de préciser. Pour illustration, nous donnons des exemples.
Dans TAPAGE, si un segment est déplacé, les segments en contact avec lui suivent le mouvement, les jonctions entre segments sont automatiquement mises à jour grâce à la structure de donnée adoptée.
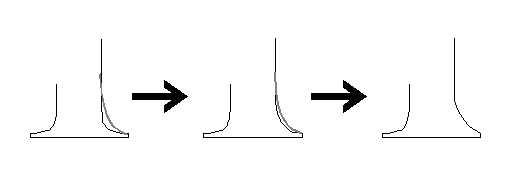
Sur la Figure 47, le déplacement de la verticale entraîne les horizontales dont les abscisses des extrémités droites pointent sur la même valeur de référence que l'abscisse de la verticale. Dans le cas d'un effacement, Figure 48, les extrémités libres sont éliminées par la disparition de la valeur de référence correspondant au segment effacé.
Nous voulons donner ici un exemple de mise en application de la production incrémentale à l'aide d'un stylo qui nous semble tout à fait intéressant puisqu'il propose des paradigmes d'interaction orignaux dans le monde de l'infographie [BAUD94].
Contrairement aux logiciels de dessin professionnels actuels, l'application décrite propose de réutiliser les composants graphiques présents sur la feuille de dessin pour les modifier en repassant dessus (Figure 49). De part leur nature, l'utilisation des courbes Splines permet une certaine souplesse et un contrôle aisé des modifications effectuées.
Les avantages de la conception incrémentale sont visibles tant du point de vue de l'utilisateur que de la machine:
Les inconvénients proviennent de la rigidité de la machine, les algorithmes d'interprétation ne laissent pas forcément l'utilisateur faire ce qu'il veut: choix à faire, options à fournir.
Nous avons présenté plusieurs méthodes de reconnaissance d'objets graphiques divers. Parfois, nous exploitons la modularité des méthodes pour les combiner et améliorer la qualité et la rapidité de la reconnaissance. Ces méthodes sont assez générales pour être réutilisées dans d'autres domaines. Il suffit de trouver les descriptions des objets à reconnaître dans un des formalismes que nous proposons.
L'interaction utilisateur-machine a fait apparaître la nécessité de traiter rapidement les données produites au stylo par le dessinateur. Les traitements et surtout la représentation interne d'un dessin ont été choisis pour minimiser les temps de calcul. La représentation choisie est basée sur la notion de références numériques pour organiser les données. La structure n'est pas explicite par opposition à une représentation par graphe (par exemple) qui serait plus analogue aux données visualisées. L'économie réalisée par cette forme de représentation est particulièrement visible quand le dessin subit des modifications locales qui sont propagées automatiquement dans la structure du tableau.
Pour s'affranchir de la contrainte de style, les seuils sont définis en fonction d'une qualité estimée du tracé et d'un seuil de base de faible valeur. La combinaison des grilles d'aimantation et des représentations par références permet de reconstruire la plupart des jonctions par des ajustement numériques aveugles, au sens où l'événement graphique traité (la jonction) n'est ni recherché ni spécifiquement traité par le système.
La séparation du module d'interprétation des tracés et du module d'interprétation des structures sera maintenue pour les futures applications. Le module sémantique pose le problème fondamental de la collaboration d'un dessinateur et d'une machine "intelligente" qui n'a à sa disposition que les règles et les conventions générales du domaine. La question de la personnalisation des interfaces implique que cette intelligence standardisée puisse aussi accepter des cas spécifiques, rares, que l'utilisateur veut produire avec l'intention de ne pas se conformer au modèle le plus général du domaine.
Il est difficile de faire une analyse qualitative des résultats fournis par nos reconnaisseurs. Ceci est dû à la conception incrémentale où l'utilisateur peut intervenir à chaque étape de la création. Nous verrons dans la partie concernant les évaluations que les premiers tests sur les tableaux n'ont pas donnés de différences significatives entre les utilisateurs novices et expérimentés pour mener à bien la recopie de tableaux.

|

|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}