Nous présentons dans ce chapitre la conception et la mise en oeuvre de la Représentation Interne de l'application interactive qui d'une part représente le point de vue du programmeur sur cette application, d'autre part est la traduction de la Représentation Conceptuelle et de la Représentation Externe.
Les possibilités de mise en oeuvre sont très différentes selon le type de logiciel de gestion d'écran dont on dispose.
On distingue les logiciels de gestion d'écran classiques gérant une seule fenêtre des logiciels plus élaborés permettant entre autre de gérer plusieurs fenêtres et que nous appelerons dans la suite de ce chapitre des systèmes de Gestion Multifenêtre ou SGM.
Nous ne détaillons pas ici les caractéristiques de logiciels de gestion d'écran classiques car ils sont bien connus des informaticiens. Nous dirons simplement qu'il en existe deux types; les plus élémentaires permettent uniquement de définir les sorties sur écran ligne après ligne alors que les plus évolués permettent de définir globalement un écran de manière interactive.
Par contre dans un premier paragraphe, nous présentons de manière détaillée les SGM (Weg,83) car ils sont encore peu utilisés alors qu'ils présentent des fonctionnalités très intéressantes pour la mise en oeuvre d'une Représentation Externe adaptée à l'utilisateur.
Dans le deuxième paragraphe, nous montrons comment mettre en oeuvre les Représentations Conceptuelle et Externe au niveau de la programmation.
La fonction principale d'un SGM est de permettre l'accès en parallèle à différentes applications et de leur donner la possibilité d'échanger des informations. Pour permettre ces accès parallèles, l'écran est divisé en fenêtres et à chaque fenêtre est associée une application.
Le SGM. est responsable de la gestion de l'écran et des différents périphériques d'entrée du système (clavier, souris, ...).
L'intérêt d'un tel SGM. est de fournir au programmeur d'application un ensemble de primitives qui lui permettront d'intégrer dans les applications une gestion très évoluée des périphériques d'entrée/sortie sans qu'il ait besoin de programmer ses fonctionnalités à chaque fois.
Le gain pour le programmeur peut être comparé au passage des systèmes de gestion de fichiers aux Systèmes de Gestion de Bases de Données. Dans le cadre d'une application bâtie sur un système de gestion de fichiers le programmeur intègre la gestion des liens entre fichiers pour chaque application particulière alors qu'il en est déchargé avec un Système de gestion de Base de Données. De la même manière, un SGM.lui permet de se décharger des problèmes d'interruption et transfert de données entre applications.
Un SGM présente également un intérêt pour l'utilisateur car il lui apporte une grande souplesse dans la gestion du dialogue.
Nous présentons tout d'abord le SGM du point de vue de l'utilisateur, puis du point de vue du programmeur et, en dernier lieu, l'exemple d'un SGM particulier.
Les fonctions principales d'un SGM. sont de permettre l'accès en parallèle à différentes applications et la communication entre applications.
La communication entre applications présente deux aspects :
- démarrage et arrêt des applications; il doit être possible d'activer de nouvelles applications à partir de celles déjà actives, sans qu'il soit nécessaire de désactiver les premières (interruption et reprise). Par exemple, l'utilisateur doit pouvoir visualiser les informations du fichier Clients alors qu'il fait une création.
- échange d'informations entre applications actives. Par exemple, l'utilisateur peut échanger une information du fichier Clients au document Facture.
En s'appuyant sur ces deux fonctionnalités (accès parallèle, communication), le SGM permet également d'effectuer la gestion des menus, des désignations, de l'écho, des erreurs, du signal et de l'aide à l'utilisation.
le menu (ensemble de commandes) autorisé à un moment donné de l'activité peut apparaître dans une fenêtre spéciale.
Il peut soit être affiché constament à l'écran, soit apparaître sur l'écran à la demande de l'utilisateur et disparaître dès qu'une commande est choisie.
Le menu peut être modifié interactivement par les activités afin de ne donner que les commandes permises à l'utisateur à un moment donné (notion de menu dynamique).
La désignation permet à l'utilisateur d'identifier un point sur l'écran ; la sélection permet d'identifier une entité logique. Une sélection peut être définie par une ou plusieurs désignations; les sélections peuvent se faire de deux façons :
- soit en désignant l'information de façon spatiale, par exemple pour supprimer une phrase, on désigne le début et la fin de cette phrase;
- soit en utilisant la stucture hiérarchique de cette information. Le parcours de cette hiérarchie peut se faire de façon ascendante (du mot au document), descendante (du document au mot) ou horizontale (information au même niveau dans différents documents).
L'idée est de renvoyer un écho (ou rétroaction) à l'utilisateur lui permettant de s'assurer que son action immédiate a bien été prise en compte par l'ordinateur.
S'il vient d'activer une commande, l'écho peut être tout simplement le résultat de l'opération (si celle-ci peut être faite immédiatement). On peut également signaler cette commande par un moyen visuel quelconque (surbrillance, inversion vidéo...). Il peut être également intéressant de signaler que l'ordinateur est en train de travailler (en cas de temps de réponse supérieur à 2 secondes) ou qu'il est en attente de paramètres de l'utilisateur.
Si l'utilisateur vient de sélecter un objet, celui-ci peut être mis en évidence comme pour les commandes (clignotements, inversion vidéo...).
Le système gère deux fonctions :
- le signalement des erreurs soit dans une fenêtre dédiée soit près d'une zone erronée.
- les commandes de rectification d'erreurs. On peut trouver des commandes comme :
"annuler" pour une exécution en cours
"arrêter" pour arrêt temporaire d'exécution
"reprendre" après un arrêt temporaire
"défaire" pour se retrouver dans l'état précédent l'activation d'une commande.
Elle permet d'indiquer à l'utilisateur qu'un évenement vient de parvenir à l'ordinateur. Par exemple, dans le cas de messages électroniques, on signalera par une icône à l'utilisateur l'arrivée d'un document dans une boîte aux lettres.
A tout moment sur demande de l'utilisateur, le système peut expliquer une commande particulière:
- l'ensemble des fonctions accessibles à un moment donné
- la documentation complète du système
- les causes possibles des erreurs.
Nous entendons par mise en oeuvre les différentes manières dont dispose l'utilisateur pour mettre en oeuvre le démarrage et l'arrêt du système et des activités, les fenêtres et les commandes
Le système dispose d'un certain nombre de valeurs par défaut.
L'identifiant au démarrage de l'utilisateur peut permettre de personnaliser le système en ce sens qu'il activera les dernières valeurs par défaut fournies par cet utilisateur.
Un autre aspect de la personnalisation consiste à conserver le contexte des activités entre deux sessions de travail de manière que l'utilisateur puisse redémarrer dans l'état où il avait arrêté son travail.
Les fenêtres sont utilisées par les différentes activités pour contenir des informations ou des menus. La fenêtre et l'application étant fortement liées, la mise en oeuvre la plus simple pour l'utilisateur consiste à créer automatiquement une fenêtre dès qu'il active une nouvelle activité et inversement à détruire automatiquement cette fenêtre lorsque cette activité est considérée comme terminée (fin de saisie de paramètres ou commande explicite de l'utilisateur).
En général, cette fenêtre est constituée de deux parties appelées clôture et cadre:
- la clôture est la partie de la fenêtre délimitant l'espace où peut être affecté l'information de l'activité. Si cette information est beaucoup plus grande que l'espace delimité par la clôture, on peut avoir une zone de défilement (ou un "page à page") commandée par l'utilisateur.
- le cadre entoure la clôture et permet de distinguer les fenêtres les unes des autres car il contient des informations permettant d'identifier la fenêtre et éventuellement des zones pour les commandes du menu.
La gestion des fenêtres implique un partage de l'écran qui peut être géré de deux manières :
- l'utilisateur choisit la taille et la position de ses fenêtres. Ces différentes fenêtres peuvent se recouvrir partiellement ou totalement. L'inconvénient est que l'utilisateur assure seul la gestion de l'écran;
- le système peut gérer complètement le partage de l'écran en optimisant l'occupation de l'écran et en interdisant le recouvrement de fenêtres. Plus on crée de fenêtres, plus la taille de chaque fenêtre diminue (on est de fait limité à 4 ou 6 fenêtres pour des raisons de lisibilité). L'utilisateur peut intervenir sur la grandeur respective des différentes fenêtres.
On peut bien sûr imaginer des variantes entre ces deux manières extrêmes. Par exemple, toute nouvelle fenêtre est créée automatiquement dans un espace libre (au besoin en diminuant la taille des autres fenêtres) et l'utilisateur peut ensuite demander un recrouvement partiel ou total, ce qui peut être utile dans le cas où un travail de fond est exécuté en parallèle avec d'autres activités.
Il peut exister des liens hiérachiques entre fenêtres :
- lien mère-fille : une opération (fermeture, ouverture, déplacement) sur la fenêtre mère entraîne automatiquement la même opération sur la fenêtre fille;
- lien frère-soeur : deux fenêtres sont soeurs si elles sont filles d'une même fenêtre. L'utilisateur ne peut travailler que sur une des soeurs à la fois (si deux fenêtres soeurs occupent un même position dans l'écran, une des deux soeurs recouvre l'autre).
Le jeu minimun de commandes de manipulation de fenêtres est le suivant :
- création de fenêtre ; cette commande peut être automatique si elle est activée par la création d'une activité. La taille et la position peuvent être choisies automatiquement ou indiquées par l'utilisateur;
- changement d'activité courante (l'activité courante est l'activité vers laquelle les entrées du clavier sont dirigées);
- changement de position et d'ordre de superposition;
- changement de taille de la fenêtre; cette modification peut soit avoir un effet de "loupe" sur l'information visualisée, soit modifier la quantité d'informations affichées. Il peut être intéressant de pouvoir résumer une fenêtre à son titre.
La plupart des commandes sont offertes explicitement à l'utilisateur soit dans le cadre des fenêtres, soit dans une fenêtre réservée au gestionnaire de fenêtres.
Si le système a des commandes génériques (valables pour toutes les activités), ces commandes peuvent être utilisées pour manipuler les fenêtres. Par exemple, la même commande peut détruire un paragraphe d'un document et d'une fenêtre.
Certaines commandes peuvent être implicites. Nous avons déjà vu que la création d'une activité peut entraîner la création d'une fenêtre. De même, le changement d'activité courante peut se faire automatiquement quand l'utilisateur désigne une fenêtre.
Nous pouvons avoir une syntaxe préfixée, postfixée ou infixée.
- Dans une commande préfixée, l'utilisateur indique le nom de la commande plus les paramètres de cette commande. Cette syntaxe est souvent considérée comme plus "naturelle" car plus proche de la manière de penser de l'utilisateur. Cette syntaxe place l'utilisateur dans un mode temporaire. En effet, après chaque commande il peut spécifier seulement les paramètres ayant trait à cette commande. Ceci est un inconvénient si l'utilisateur veut utiliser plusieurs commandes et si on veut conserver la simplicité de la syntaxe.
- Dans une commande postfixée, l'objet à traiter est spécifié en premier et il est suivi par l'opération à accomplir. Cette syntaxe, plus simple que la précedente pour les commandes à un paramètre, s'adapte mal aux commandes à plusieurs paramètres, si on veut conserver la simplicité de syntaxe.
- La syntaxe infixée est intermédiaire entre la postfixée et la préfixée.Les paramètres entourent la commande, ce qui rend simple une commande à deux paramètres, sinon on cumule les inconvénients des deux autres syntaxes.
Nous présentons dans ce paragraphe l'architecture générale d'un SGM puis les propriétés principales et enfin les possibilités de mise en oeuvre (Cou, 86).
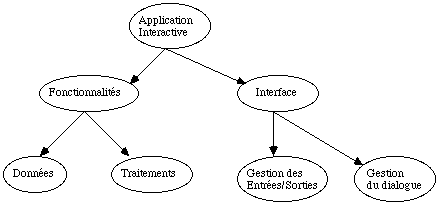
L'idée essentielle sur l'architecture interne d'un logiciel d'application interactive est de séparer au niveau du code les fonctionnalités concernant l'application de celles concernant l'interface homme/ordinateur.
Cette idée est justifiée par le fait que les fonctionnalités de l'application sont par définition spécifiques à chaque application alors qu'une partie importante des caractéristiques de l'interface est indépendante de toute application (voir les paramètres constants de la Représentation Conceptuelle).
Les fonctionnalités sont décomposées en données et traitements, d'une part pour les facilités ultérieures de modification, d'autre part pour minimiser la programmation en utilisant des systèmes de gestion de base de données.
L'interface est subdivisée en gestion des entrées/sorties, totalement indépendante de l'application, et gestion du dialogue qui fait le lien entre les entrées/sorties et les fonctionnalités de l'application.
L'architecture d'un SGM peut être fermée ou ouverte:
- architecture fermée
Pour cette architecture le SGM est vu comme un tout, fournissant un ensemble bien défini et indissociable de services.
Ce type d'architecture permet de rendre tranparents les détails d'implantation et les particularités de la machine, et d'être "insensible" aux erreurs éventuelles des programmeurs d'applications.
L'inconvénient majeur est que cette structure permet difficilement l'évolution vers de nouvelles activités et ne permet pas aux programmeurs d'application d'utiliser de manière particulière les différentes fonctionnalités du SGM.
- architecture ouverte
Cette architecture permet au programmeur d'utiliser tous les niveaux de services dont il a besoin et ainsi d'utiliser des parties du SGM pour les besoins propres de l'activité. Il faut cependant noter qu'une architecture totalement ouverte ne peut garantir un partage équitable des ressources dans un système multiutilisateur.
L'architecture ouverte, pour être opérationnelle, nécessite que :
- chaque module soit effectivement indépendant des autres (pas d'effets de bord, pas de références croisées)
- les services offerts par chaque niveau doivent se limiter au strict nécessaire afin de ne pas nuire aux extensions ultèrieures.
Par exemple, la gestion des fenêtres ne gère qu'un niveau de fenêtres (pas les sous-fenêtres) ce qui permet au programmeur d'utiliser ces fonctions de gestion de fenêtres à l'intérieur d'une fenêtre propre à une activité. Alors qu'une gestion de fenêtres plus élaborée gérant dès le départ toute une arborescence de fenêtres n'aurait pas permis une réutilisation facile pour le programmeur.
Toute fonction qui concerne plusieurs niveaux de services doit être définie dans un seul niveau, de priorité plus élevée. Par exemple, le changement d'activité courante.
Il est défini par l'unité d'échange entre l'application et l'interface; cette unité d'échange peut évoluer entre deux extrêmes; elle peut concerner des événements élémentaires comme la prise en compte du "clic" de la souris ou des événements synthétiques comme une commande complète et syntaxiquement correcte.
Ce niveau d'abstraction joue un rôle important pour la facilité de mise en oeuvre de la programmation; en effet, un niveau d'abstraction trop bas correspondant à des événements élémentaires rend le travail du programmeur lourd et complexe tout en lui donnant le maximum de latitude. L'idéal est bien sûr est d'avoir un niveau d'abstraction élevé tout en se réservant la possibilité de commandes plus élémentaires pour résoudre des cas particuliers.
Le contrôle du dialogue correspond aux possibilités d'enchaînement des opérations qui, dans le cas général, sont réparties entre l'utilisateur et la machine; le contrôle spécifie donc les enchaînements automatiques aussi bien que les déclenchements utilisateurs.
Le contrôle peut se faire dans l'application ou dans l'interface.
Il est plus usuel de mettre le contrôle dans l'application et plus précisément dans les traitements, mais cette pratique a l'inconvénient de rendre complexe sinon impossible la modification de ce contrôle par le programmeur et encore plus par l'utilisateur. Aussi, si on veut pouvoir intégrer de nouvelles procédures effectives, il est préférable de mettre ce contrôle dans l'interface.
Par contre, on peut envisager un contrôle réparti entre l'application et l'interface dans le cas où on a un traitement dirigée par les données, c'est-à-dire quand les enchaînements dépendent au niveau du logiciel de la valeur des données; c'est plus précisément le cas dans les systèmes d'aide à la décision et en particulier dans les systèmes experts.
Nous distinguons le parallélisme géré par l'ordinateur du parallélisme tel qu'il est perçu par l'utilisateur.
Le parallélisme géré par l'ordinateur consiste à faire travailler en parallèle soit plusieurs périphériques, soit plusieurs applications, soit plusieurs utilisateurs.
Ces fonctions sont prise en compte par le système d'exploitation de la machine.
Le parallélisme perçu par l'utilisateur correspond à la possibilité de ce dernier d'interrompre à tout instant une application pour en activer une autre en gardant présent sur l'écran l'image de ces différentes applications. Cette fonction est rendue possible et praticable pour l'utilisateur par la gestion du multifenêtrage au niveau de l'interface, ce multifenêtrage s'accompagnant ou non de multitâche. La fonction de multitâche (ou parallélisme de la machine) a un impact sur le temps de réponse alors que le fonction de multifenêtrage facilite le travail de l'utilisateur.
Nous parlons ici du contexte de l'interaction entre l'homme et la machine. La plupart du temps ce contexte n'est pas pris en compte par le logiciel .
On peut distinguer plusieurs formes de contexte:
- le contexte de l'utilisateur qui permet de prendre en compte différents types d'utilisateur
- le contexte des objectifs du travail qui est révélé par la logique d'utilisation
- le contexte de la transaction qui permet de savoir où l'on se situe par rapport aux objectifs recherchés.
La gestion de ces différents contextes a un impact sur le guidage, le traitement des erreurs et l'adaptabilité aux utilisateurs.
On peut distinguer l'adaptation gérée automatiquement par l'ordinateur de l'adaptation déclenchée par l'utilisateur. Dans les deux cas, il s'agit de la possibilité de modifier le logiciel pour s'adapter à de nouveaux besoins.
L'adaptation automatique du logiciel est abordée en intelligence artificielle et réalisée dans certains didacticiels.
L'adaptation déclenchée par l'utilisateur n'est possible que si le logiciel est structuré en ce sens; d'où l'importance d'une architecture modulaire des logiciels interactifs telle que nous la présentons ici et qui est une condition nécessaire à toute recherche d'adaptabilité.
L'utilisation d'un SGM implique un style de programmation particulier que l'on qualifie de "dirigée par les événements".
Le programme est conçu comme une boucle appelant régulièrement une procédure qui lui fournit l'événement suivant disponible et qui aiguille le programme vers l'action concernée, en fonction du type d'événement reçu et de l'état courant du programme.
Ce mode de fonctionnement s'apparente aux automates d'états finis où l'état suivant est fonction de l'état courant et de l'événement qui provoque la transition.
Actuellement, les SGM se présentent sous deux formes: les "boîtes à outils" et les systèmes génériques. Les premiers sont disponibles sur le marché alors que les seconds sont en développement.
Les "boîtes à outils" sont constituées d'un ensemble de fonctions dédiées à l'interface homme/machine.
Il existe des fonctions à des niveaux d'abstraction très divers; les fonctions élémentaires gèrent des événements comme l'appui sur une touche du clavier ou le cliquage sur la souris alors que d'autres plus synthétiques permettent de gérer les menus.
Les "boîtes à outils" sont des systèmes à architecture ouverte où le programmeur a un maximum de latitude, mais en contrepartie il a à gérer tous les détails de l'interaction ce qui est à la fois complexe et lourd.
Les systèmes génériques fournissent des formes standard à partir desquels on va développer l'application; ils permettent aussi parfois une définition interactive des ressources (dessin d'une fenêtre, d'une icône,...). Ces systèmes sont bâtis sur une boîte à outils; ils peuvent donc avoir une architecture ouverte ou fermée selon que l'on peut ou non accéder aux fonctions de la boîte à outils.
L'objectif de ces systèmes génériques est de faire gagner du temps de programmation quitte à perdre un peu de souplesse. C'est certainement la voie d'avenir pour le plus grand nombre de programmeurs d'application.
Le SGM de Macintosh est constitué d'une part d'un ensemble de primitives implantées en ROM, d'autre part d'un ensemble de fonctions logicielles regoupées dans la "boîte à outils".
Ces primitives et fonctions sont présentées dans le formalisme PASCAL mais sont également accessibles à partir de tout langage permettant l'exécution de l'instruction TRAP.
Les fonctions de la "boîte à outils" sont regoupées en modules selon le type d'objets qu'elles manipulent; cette structuration correspond à une approche "langage-objet".
Les modules concernant directement l'interface sont:
- le gestionnaire de ressources
- le gestionnaire d'événements
- le gestionnaire de fenêtres
- le gestionnaire de contrôles
- le gestionnaire de menus
D'autres modules sont disponibles pour la programmation de l'application elle-même; ce sont les gestionnaires d'impression, de fichiers, de mémoire.
Les ressources sont l'ensemble des objets (fenêtres, messages, icônes,...)qui vont être gérés par l'interface; dans ce module on décrit leurs caractéristiques comme, par exemple, la taille d'une fenêtre.
Le fait de décrire ces ressources dans un module séparé permet d'effectuer aisément des modifications.
Il existe des ressources système, accessibles par toute application sans définition préalable.
Le gestionnaire de ressources permet la gestion de l'espace mémoire occupé par ces ressources.
Ce sont les événements d'interaction avec l'utilisateur, on trouve les événements suivants:
- l'événement "souris" indique que l'utilisateur vient de presser ou de relacher la souris
- l'événement "clavier" indique que l'utilisateur presse ou relache une touche
- l'événement "disque" se produit si l'utilisateur introduit une disquette dans un des lecteurs
- l'événement "d'activation" est généré par le gestionnaire de fenêtres lorsqu'une fenêtre devient active ou inactive
- l'événement de "mise à jour" se produit si une partie du contenu d'une fenêtre doit être dessinée ou redessinée par le programme
- l'événement "réseau" est généré par le gestionnaire du réseau d'ordinateurs quand il existe
- l'événement "privé" peut être défini par n'importe quelle application spécifique
Les événements sont stockés dans une file d'attente gérée en FIFO (premier entrée/premier sortie) mais où on peut définir des priorités.
Il permet de manipuler les fenêtres, c'est-à-dire de les ouvrir, de faire varier leur taille, de les déplacer, de les détruire...
Comme l'utilisateur est libre de superposer ces fenêtres, c'est le gestionnaire de fenêtres qui va gérer cette superposition.
Il permet également de donner des réponses standard à certaines actions de l'utilisateur comme:
- rendre active une fenêtre après "cliquage" de la souris dans cette fenêtre
- fermer une fenêtre après "cliquage" dans l'icône de fermeture
- déplacer une fenêtre après "cliquage" sur la barre de titre.
Il existe des fenêtres prédéfinies mais il est possible de définir de nouveaux types de fenêtres.
Les contrôles sont des objets graphiques prédéfinis (boîtes, boutons, barres de défilement) qui permettent de proposer des choix à l'utilisateur. On peut les utiliser, par exemple, pour définir les paramètres d'une impression. Les barres de défilement permettent à l'utilisateur de faire glisser le contenu d'une fenêtre de manière à visualiser plus d'informations que ne peut en contenir une fenêtre.
L'utilisateur agit sur ces contrôles par l'intermédiaire de la souris.
Le gestionnaire de menus
Il permet la manipulation de "menus déroulants" qui apparaissent sur l'écran uniquement quand l'utilisateur appuie sur la souris.
Il permet également d'activer ou de désactiver des commandes du menu ce qui est utile pour visualiser un menu dynamique.
Nous pouvons constater que beaucoup de ces fonctions présentées dans le formalisme PASCAL sont de bas niveau et demandent donc un travail important de programmation.
Par contre, il existe en LELISP un certain nombre de fonctions de haut niveau qui permettent une mise en oeuvre rapide qu'il peut être intéressant d'utiliser pour construire un prototype d'interface.
Nous présentons ici des SGM développés sous UNIX de manière générale et d'un système particulier également sous UNIX : BRUWIN (Mer, 81).
Les SGM. développés sous UNIX offrent à l'utilisateur une commande explicite de création de fenêtre. Celle ci associe automatiquement un interpréteur de commande (shell) à la fenêtre créée, ce qui garantit l'indépendance des programmes qui s'éxécutent dans les différentes fenêtres.
La compatibilité des SGM avec UNIX est assurée de la manière suivante :
- le gestionnaire de fenêtre doit collaborer avec le gestionnaire de fichiers. En effet, dans UNIX, toutes les entrées/sorties se font au moyen de fichiers spéciaux. Les programmes d'application accèdent à leur fenêtre par leur fichier standard d'entrée ou de sortie ; ainsi chaque fenêtre simule un clavier : écran alphanumérique (il faut créer des procédures spéciales pour pouvoir dessiner dans une fenêtre);
- ces différents fichiers spéciaux sont gérés à l'aide d'appels systèmes qui sont également utilisés pour gérer les fenêtres puisqu'elles sont considérées comme des fichiers spéciaux;
- la description du contenu de la fenêtre peut être gérée entièrement par le SGM ou bien déléguée au programmateur d'application. Dans ce cas, le SGM a une routine d'interruption qui permet d'activer le programme qui s'occupe de l'affichage du contenu;
- les SGM sont intégrés au moyen d'UNIX car c'est la seule méthode qui permet de partager, entre plusieurs programmes à la fois, du code et des données.Certains opérateurs offerts par les systèmes UNIX font double emploi avec un SGM:
. l'opérateur postfixe "&" qui permet d'activer une commande sans attendre que celle qui est active soit terminée
. l'opérateur préfixe "!" qui permet d'envoyer directement une commande à l'interpréteur de commandes sans quitter son programme.
Exemple de SGM sous UNIX : BRUWIN
Le système BRUWIN (Brown University Window Manager) est un des premiers SGM réalisés sous UNIX. Il fonctionne avec des terminaux alphanumériques permettant de désigner un point sur l'écran.
Il offre deux modes d'utilisation :
- le mode processus pour communiquer avec le programme en exécution dans la fenêtre courante
- le mode commande pour communiquer avec le gestionnaire de fenêtres.
Ce mode offre les commandes suivantes :
. cancel : supprime l'exécution de la commande BRUWIN en cours
. create : crée une fenêtre (associée à l'interpréteur de commande)
. change : modifie la taille d'une fenêtre
. move : déplace une fenêtre
. destroy : détruit une fenêtre et son interpréteur de commandes
. command : change de fenêtre courante.
BRUWIN est divisé en trois modules principaux :
. un module gestionnaire de fenêtre qui est responsable de la division de l'écran en fenêtres, de la mise à jour de l'écran et de la gestion des commandes de manipulation de fenêtres;
- un module émulateur de terminal virtuel qui permet l'adaptation à différents tyes de terminaux.
. un module contrôleur de tâches qui assure le lien entre BRUWIN et le système d'exploitation. Il est également responsable de l'envoi des caractères au programme d'application courant.
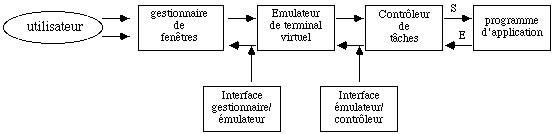
L'indépendance entre ces trois modules est assurée par deux modules interface (gestionnaire / émulateur et émulateur / contrôleur) ; ce qui permet de modifier l'un d'entre eux sans modifier l'ensemble.
Cet exemple montre que le SGM, tel que nous l'avons défini, peut être vu comme une extension du système d'exploitation, UNIX se prétant bien à ce genre d'extension.
La Représentation Interne n'est traitée ici que très succintement par le biais de son architecture générale, car une présentation détaillée dépasserait par le thème et le volume le cadre de ce livre:
- par le thème, car il serait nécessaire de rentrer dans le détail des structures de contrôle comme les Réseaux de Petri et dans le détail des techniques de programmation alors que ce livre est centré sur l'analyse et la spécification des applications interactives;
- par le volume, car un tel développement nécessite à lui seul un livre.
La R.I. est la traduction des Représentations Conceptuelle et Externe. Normalement toutes les spécifications ont déjà été faites et le passage à la R.I. est une simple traduction sans génération de nouvelles spécifications.
Notre objectif principal est de permettre la conception et la réalisation d'interfaces le plus adaptative possibles. Cette préocupation se traduit dans la conception de l'architecture générale de la R.I.
Les modifications de programmes sont d'autant plus aisées que les différentes fonctionnalités sont séparées de telle manière que la modification d'un élément n'ait pas de répercussions sur les autres éléments (sauf au niveau de l'interfaçage des différentes fonctionnalités).
Nous représentons cette architecture générale sur le schéma suivant :
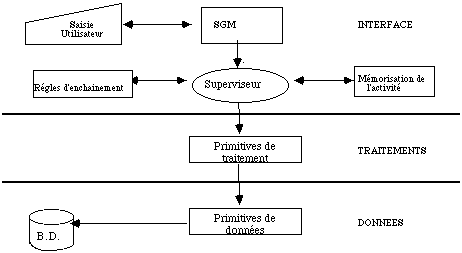
Nous définissons une primitive comme un élément indécomposable vis-à-vis du système informatique, de même qu'une opération élémentaire est un élément indécomposable vis-à-vis de l'utilisateur.
Les primitives de traitement décrivent les algorithmes de calcul.
Les primitives de données décrivent les contrôles de vraisemblance, de concordance, la recherche et la mise à jour des données.
Les règles d'enchaînement décrivent les différentes procédures (prévues, minimales et effectives).
La mémorisation de l'activité des utilisateurs permet de gérer les interruptions, les différés, les aides et l'état d'avancement de la transaction en cours.
Le superviseur joue un rôle central d'activation des différents modules en fonction du contexte; il a un double rôle d'enchaînement des opérations et de contrôle de la validité de ces enchaînements.
Le SGM détermine la nature de l'événement reçu (clavier, lecteur,...) et le traite s'il relève seulement de la syntaxe (déplacement fenêtre, changement de taille,...); s'il relève de la sémantique de l'application (commandes,...), il active le superviseur.
Les différents modules que nous venons de définir n'ont pas le même statut; certains ont un caractère général alors que d'autres sont entièrement définis pour chaque application . Nous présentons ces différents modules en précisant leurs rôles et leurs structures.
C'est le module qui a le caractère le plus général, c'est-à-dire qu'il est totalement indépendant de tout type d'application.
Le superviseur a deux fonctions imbriquées :
- une fonction d'enchaînement,
- une fonction de contrôle.
Il reçoit les demandes d'actions de l'utilisateur à travers le SGM.
Il contrôle le fait que la demande de l'utilisateur est compatible avec les règles d'enchaînement et la mémorisation de l'activité.
Si tel est le cas, il active les traitements demandées et il met à jour la mémorisation de l'activité.
Il renvoie des messages à l'utilisateur par le biais du SGM.
De plus il gère les abandons, les reports, les interruptions (dans le cas où cette dernière fonction n'est pas prise en compte par le SGM) par des mises à jour du module de mémorisation de l'activité.
Pour ces modules nous avons deux possibilités de représentation: les automates d'états finis et les Réseaux de Petri.
La représentation sous forme d'automates d'états finis est maintenant classique et bien connue des informaticiens; la représentation visuelle est simple et la transposition sous forme vectorielle facile. Le seul inconvénient est qu'elle ne permet pas une gestion aisée du parallélisme.
Le parallélisme étant une composante essentielle des traitements en informatique des organisations et dans les interfaces homme/machine, il est plus exact d'utiliser le formalisme des Réseaux de Petri (Bra, 83) et plus précisément les Réseaux de Petri à Objets (Sib, 85) et (Bar, 86) qui ont l'avantage de permettre l'expression des interactions entre les données et les traitements.
Nous incluons dans ces modules les primitives de :
- contrôle de données (vraisemblance et concordance)
- gestion de données
- gestion de traitements.
La définition de ces primitives est entièrement particulière à chaque application.
Elles sont définies pour chaque opérations interactive ou automatique.
L'architecture que nous venons de présenter correspond aux possibiltés maximales de mise en oeuvre des fonctionnalités des logiciels interactifs; il n'est pas évident de réunir l'ensemble des logiciels et des compétences permettant ce type de mise en oeuvre; nous examinons ce qui peut être fait si certains des composants sont absents:
- si on ne dispose pas d'un interpréteur de Réseau de Petri, on peut gérer les enchaînements et la mémorisation de la transaction au moyen de vecteurs booléens qui traduisent le comportement de l'automate d'état fini; ceci sera praticable tant que le parallélisme est faible;
- si on ne dispose pas d'un SGM, certaines fonctionnalités comme la gestion des interruptions peuvent être prises en charge par le superviseur ou éventuellement par une modification du système d'exploitation; par contre, la plupart des fonctionnalités offertes directement à l'utilisateur comme le déplacement de fenétres ou leur superposition ne peuvent plus raisonnablement être gérées;
- si on adopte une architecture de programmes plus classique où l'on ne distingue pas l'interface et les traitements, on se prive de possibilités de modification et en particulier d'adaptation après des tests auprès des utilisateurs; mais on peut quand même mettre en oeuvre les recommandations ergonomiques à caractère général .