Ce chapitre a pour but de présenter les principes de conception de la Représentation Externe qui correspond à ce que voit l'utilisateur de l'application interactive.
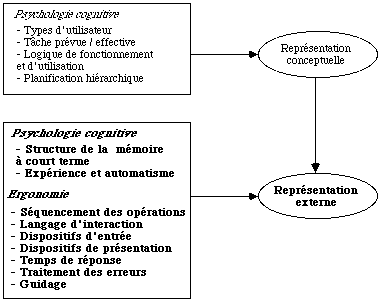
Comme nous le rappelons dans le schéma ci-dessous, la Représentation Externe provient d'une part des concepts de la Représentation Conceptuelle, d'autre part de critères de psychologie cognitive ou d'ergonomie.
Il faut aussi noter que la conception de la Représentation Externe est fortement dépendante de contraintes techniques qui sont d'une part les caractéristiques physiques de l'écran, d'autre part les logiciels de gestion d'écran. Pour mettre en valeur ces contraintes, nous donnons des exemples de mise en oeuvre avec un logiciel de gestion d'écran classique et avec un logiciel de multifenêtrage.
Ce chapitre est divisé en trois parties.
Dans la première partie, nous présentons les connaissances de psychologie cognitive sur la structure de la mémoire et sur l'apprentissage car elles permettent de mieux comprendre le fondement des recommandations ergonomiques.
Dans la deuxième partie, nous exposons les recommandations ergonomiques concernant les sept paramètres de l'interface et nous citons des expériences d'observations directes.
Dans la troisième partie, nous montrons comment intégrer ces éléments à la conception de la Représentation Externe compte-tenu des contraintes des logiciels de gestion d'écran.
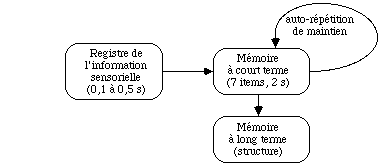
La perception et l'enregistrement d'une information quelconque chez l'être humain met en cause trois types de mémoire:
- un registre de l'information sensorielle qui est capable de contenir l'intégralité d'une image pendant un temps trés court (de 0,1 à 0,5 secondes),
- une mémoire à court terme qui interprète les informations contenues dans le registre de l'information sensorielle afin d'en extraire les éléments significatifs,
- une mémoire à long terme que l'on peut considérer comme sans limite par rapport à la longueur d'une vie humaine.
Nous ne développons pas ici les caractéristiques du registre de l'information sensorielle car elles relèvent de la perception physiologique et concernent par conséquent l'ergonomie du matériel. Les mémoires à court terme et à long terme ont par contre un impact important sur l'ergonomie du logiciel.
La mémoire à court terme constitue une limite énorme pour l'être humain; en effet et schématiquement, elle ne peut retenir que 7 items pendant un délai de deux secondes.. Un item correspond à une unité d'information significative pour un individu.
Exemple d'items:
H C T correspond à trois items
CHAT correspond à un item (pour une personne connaissant le français)
Le chiffre de 7 items correspond à une moyenne qui fluctue entre un minimum de 5 et un maximum de 9 selon les personnes.
Le délai de deux secondes de rétention de l'information sans altération et sans effort est un minimum atteint par tout le monde. Au-delà, cette information s'altère avec le temps; au bout de trois secondes, il n'y a plus que 80% de réponses justes et à six secondes 40%. Si l'on désire conserver une information plus longtemps dans la mémoire à court terme, il est nécessaire de procéder à une autorépétition de maintien qui consiste à répéter mentalement cette information jusqu'à son utilisation.
C'est ce que nous pratiquons spontanément quand nous voulons nous souvenir d'un numéro de téléphone que nous ne pouvons écrire immédiatement.
L'effacement de la mémoire à court terme se produit spontanément avec le temps, mais il peut être provoqué aussi par interférence avec d'autres informations; en effet, l'arrivée de nouvelles informations que nous désirons mémoriser effacera une partie ou la totalité des informations présentes dans la mémoire à court terme et ces dernières seront définitivement effacées si nous n'avons pas eu le temps de les faire basculer de la mémoire à court terme vers la mémoire à long terme ou de les transcrire sur papier.
Les mécanismes de mémorisation et de recherche dans la mémoire à long terme ne sont pas connus avec autant de précision que ceux de la mémoire à court terme.
Cependant, nous savons que l'effort de mémorisation dans la mémoire à long terme requiert une concentration qui nous rend relativement indisponible pour d'autres tâches. Par exemple, nous savons qu'il est difficile pour un étudiant d'écrire complétement une phrase entendue et de la mémoriser en même temps; cette difficulté est accrue s'il ne comprend pas cette phrase. Ce dernier phénomène est dû, d'une part aux limites de la mémoire à court terme, d'autre part au fait que la mémorisation dans la mémoire à long terme est facilitée par la compréhension et par la possibilité de rattacher toute nouvelle information à une information déjà existante dans nos structures mentales. En d'autres termes, il est plus facile de retenir une information dans un domaine connu et qui complète des informations que nous possédons déjà ou dit autrement "plus on sait, plus on est capable d'apprendre".
Ce fait explique l'intêret du raisonnement par analogie qui permet de comparer un phénomène inconnu à un phénomène connu.
La notion de compréhension est liée à la notion de structure de l'information; cela suppose que l'information que l'on veut mémoriser a une structure significative et que cette structure a une correspondance avec la structure des informations que nous possédons déjà. Une conséquence immédiate est qu'une information strcturée est plus facilement mémorisable.
A partir de ces faits, différents modèles explicatifs du fonctionnement de la mémoire ont été élaborés, mais nous ne les exposerons pas ici car il ne s'agit que d'hypothèses et ils n'ont pas de conséquences pratiques en ergonomie du logiciel.
Les conséquences de cette structure de la mémoire sur les interfaces sont multiples:
- une simple interruption (téléphone, client,...) crée un effacement de la mémoire à court terme; pour remédier à cette limite, il est nécessaire de mémoriser l'activité de l'utilisateur de manière à pouvoir lui rappeller ces dernières actions, de lui signaler ces erreurs le plus tôt possible, de lui signaler les conséquences de ces actions,
- la dégradation rapide de l'information de la mémoire à court terme avec le temps doit être prise en compte dans la conception du paramètre "temps de réponse",
- les limites de capacité en quantité d'information de la mémoire à court terme nécessitent la concision et l'emploi de concepts les plus agrégés possibles sous la forme la plus identifiable correspondant ainsi (après apprentissage) à un seul item,
- la mémorisation en mémoire à long terme est facilitée par la compatibilité entre les anciennes et les nouvelles procédures ou par des analogies avec des systèmes connus.
Nous avons déjà parlé dans le chapitre précédent de la différence entre utilisateurs novices et utilisateurs expérimentés en insistant sur le fait qu'ils n'ont pas la même représentation de leur travail, nous voulons présenter ici une autre différence qui a un impact important sur les interfaces.
L'utilisateur qui répète souvent les mêmes tâches sur des périodes suffisamment longues acquiert des automatismes qui lui permettent d'exécuter ces tâches très rapidement et avec une mobilisation minimale de ces processus conscients.
En effet, l'exécution de ces tâches devient en partie ou totalement inconsciente et l'efficacité du travail s'en trouve notablement accrue. Par analogie avec l'ordinateur, on pourrait dire que ces tâches sont devenues "cablées".
Nous pouvons citer comme exemple l'apprentissage du clavier ou la conduite de sa voiture sur un itinéraire quotidien.
De manière schématique, nous pouvons même dire qu'un des objectifs essentiels de tout apprentissage est de créer chez l'individu le maximum d'automatismes pour toutes les tâches répétitives afin de lui permettre de dégager le maximum de temps pour des activités plus rares et plus complexes.
Une conséquence immédiate de cette connaissance est que la conception de l'interface doit favoriser la création de ces automatismes. Pour cela nous devons concevoir tous les paramètres avec le maximum d'homogénéité.
En effet, la création d'automatismes ne peut se produire que si dans toutes les situations identiques l'action de l'utilisateur est la même.
Par exemple, la touche permettant de valider l'entrée des données doit être la même pout toutes les applications informatiques.
Ce souci d'homogénéité a un impact sur presque tous les paramètres de l'interface:
- en entrée: touches/fonction ou souris
- en sortie: disposition spatiale de l'écran
- erreurs: présentation et rectification
- langage: syntaxe et vocabulaire
- séquencement: procédure d'enchaînement
- guidage: présentation et concepts
Comme nous l'avons vu au chapitre 1, l'interface vue par les ergonomes se décompose en sept paramètres qui sont:
- le séquencement des opérations
- le langage d'interaction
- les dispositifs d'entrée
- les dispositifs de sortie
- le temps de réponse
- le traitement des erreurs
- le guidage
Mais ces paramètres ne sont pas homogénes et, en particulier, ils ont des impacts différents sur l'utilisateur.
Pour illustrer ce fait, mous présentons une modélisation de l'opérateur en trois niveaux faite par Falzon (Fal, 82) à propos du contrôle aérien:
- Le premier niveau concerne les caractéristiques physiologiques de l'opérateur; il fait référence aux travaux concernant la perception physiologique comme, par exemple, les limites de lisibilité sur un écran, la fatigue visuelle, etc...
- Le deuxième niveau concerne le traitement par l'utilisateur des opérations élémentaires. La mémorisation du vocabulaire ou l'utilisation correcte d'une syntaxe fait partie de ce niveau .
Ce niveau regroupe les aspects lexicaux et syntaxiques utilisés en linguistique.
- Le troisième niveau concerne le système de représentation et de traitement de l'information de l'utilisateur qui lui permet de synthétiser, résoudre un problème en fonction des informations disponibles. Par exemple, la représentation d'une procédure de traitement ou la résolution d'un problème fait partie de ce dernier niveau.
Ce niveau regroupe les aspects sémantiques et contextuels de la linguistique.
Si on considère les différents paramètres de l'interface, on s'aperçoit qu'ils n'ont pas le même statut vis-à-vis des trois niveaux de l'utilisateur. Par exemple, le séquencement des opérations fait appel aux niveaux II et III de l'utilisateur.
Nous pouvons représenter l'ensemble de ces effets sur le tableau
suivant :

Dans la suite de ce travail, nous ne nous intéressons pas aux effets physiologiques qui relèvent de l'ergonmie du matériel mais seulement aux niveaux II et III qui relèvent de l'ergonomie du logiciel. Aussi, nous n'exposerons pas ici les effets physiologiques des disposifs d'entrée et de sortie bien qu'ils aient fait l'objet de très nombreux travaux en ergonomie.
Nous présentons des recommandations ergonomiques sur les sept paramètres énumérés précédemment.
Le sujet est trop récent pour que ces recommandations soient exhaustives et en outre la combinaison de ces recommandations peut aboutir à des contradictions partielles qui ne peuvent être levées que par une expérimentation auprès des utilisateurs.
Le problème évoqué ici est celui de l'adéquation entre l'ordre des opérations fixé par la machine et celui nécessaire à l'opérateur pour effectuer sa tâche dans n'importe quel environnement.
En effet, la plupart du temps la conception de l'interface se fait en fonction du déroulement normal (tâche prévu) ou moyen de la tâche sans tenir compte des types d'utilisateurs (expérimenté / novice) ou d'aléas provenant de l'environnement; alors que, ces éléments constituent le contexte naturel de toute tâche effectuée par un être humain .
Nous rapellons que la plupart des caractéristiques du séquencement font partie de la structure profonde des logiciels et sont à ce stade déjà déterminées, il s'agit :
- du type d'enchaînement (libre, guidé, automatique)
- des possibilités d'enchaînements variés selon le degré d'expérience et le type d'utilisateur
- d'accéder à toutes les informations avec autant ou plus de facilité qu'à la main
- de pouvoir quitter ou annuler à tout moment
- d'interrompre à tout moment une transaction en cours soit pour un temps bref (consultation), soit pour la reprendre ultérieurement (différer)
- d'afficher ce que l'on vient de faire afin de reprendre plus facilement après une interruption
- de faire appel à une opération quelconque à partir d'une autre et de revenir en arrière
- de transférer des informations d'une opération à l'autre.
La partie externe du logiciel devra permettre à l'utilisateur d'exécuter le plus facilement possible l'ensemble des possibilités ainsi offertes c'est-à-dire qu'au niveau de l'interface, il faudra traduire ces caractéristiques en:
- dispositifs de sortie et d'entrée
- vocabulaire et syntaxe
- messages d'erreur et guidage,
ainsi que nous allons le voir dans les paragraphes suivants.
Le langage d'interaction est l'outil qui va permettre à l'utilisateur d'exprimer, au moyen d'un vocabulaire et d'une syntaxe, les opérations qu'il désire faire effectuer à la machine. Ces opérations portent sur des commandes et / ou des données.
De façon unanime, les ergonomes privilégient l'emploi du langage des spécialistes de la tâche plutôt qu'un langage d'informaticien. Or, à l'heure actuelle, on ne peut pas dire que l'on trouve ce type de langage dans tous les logiciels développés.
A celà, plusieurs raisons :
- la première, de fond, est liée à la définition même du langage d'interaction qui est un compromis entre les tâches de l'utilisateur et les fonctions informatiques
- la seconde, plus circonstancielle, est liée au fait que ces langages sont conçus par des informaticiens qui pensent en fonction de la machine et de leur propre formation (voir l'étude faite par Scapin (Sca,81) d'un langage de messagerie électronique )
- la dernière est liée à la création de tâches nouvelles ou traitées différemment à cause de l'automatisation (traitement de texte, messagerie électronique) et qui nécessitent donc très souvent la création d'un vocabulaire nouveau.
Dans le cas où l'on ne peut utiliser des mots du vocabulaire courant ou du vocabulaire professionnel en leur conservant le même sens, que peut-on choisir comme vocabulaire du langage de commande :
- des codes numériques ?
- des codes mnémoniques ?
- des mots de la langue française ?
- des mots inconnus ?
- des pictogrammes?
Les codes numériques font l'unanimité contre eux par leurs difficultés à être mémorisés et les risques d'erreurs élevés. Leurs seuls avantages résident dans le fait qu'ils sont courts et donc rapides à saisir.
Cependant les codes numériques qui peuvent être décomposés selon une structure connue sont plus faciles à mémoriser (comme nous l'avons vu pour la mémorisation à long terme).
Les codes mnémoniques sont préconisés assez fréquemment mais sans qu'il y ait accord sur leurs règles de fabrication : faut-il prendre la première lettre du mot, les deux premières lettres, les trois premières lettres ou d'autres ? Nous manquons ici d'expériences sérieuses nous disant quelles règles de troncatures assureraient une meilleure mémorisation et un moindre risque d'erreur. Peut-être n'existe-t-il pas de règles générales et faut-il tester ceci pour chaque langage ? Certains préconisent de laisser aux utilisateurs le soin de créer eux-mêmes leurs prores abréviations à partir des mots complets.
Les mots du langage naturel : de nombreux informaticiens estiment que l'utilisation du langage naturel est ce que l'on peut offrir de mieux à l'utilisateur. C'est pourquoi l'évaluation d'un langage (Sca,81) développé dans le cadre d'une messagerie électronique est intéressante car le résultat est absolument contre-intuitif. En voici les principales conclusions :
- le vocabulaire est mieux compris par les informaticiens que par les utilisateurs naïfs ; ce résultat provient du fait que ce vocabulaire ayant été choisi par les informaticiens (inconsciemment en fonction de leur culture), les mots utilisés avaient un sens différent dans le contexte informatique par rapport au langage courant
- les termes choisis ne sont pas évidents sans apprentissage
- il y a de nombreuses confusions dues à des problèmes de synonymie et d'indétermination syntaxique
- la mémorisation est très mauvaise car il semble, à la limite, plus difficile de mémoriser un mot connu avec un nouveau sens que de mémoriser un mot nouveau
Les mots inconnus (créés ou issus d'une langue étrangère) : il n'y a plus de risque de confusion comme précédemment, mais il y a un effort de mémorisation plus important.
Les pictogrammes peuvent se révéler très intéressants quand ils sont sans ambiguïté pour l'utilisateur; leur intérêt réside dans le fait qu'ils permettent d'exprimer un concept sous un seul item facilement mémorisable dans la mémoire à court terme, et qu'ils peuvent permettre l'analogie avec un cas manuel connu ce qui facilite la mémorisation à long terme.
De tout cela, se dégage le fait qu'il n'y a pas une solution qui l'emporte nettement; il y a donc lieu de procéder par expérimentation dans chaque cas. D'où l'intérêt d'un prototype d'interface sur lequel on peut expérimenter et que l'on peut modifier aisément.
Ce sont les règles qui permettent d'exprimer les commandes ou les données et de les combiner entre elles.
Les diverses études se rejoignent sur la nécessité de deux caractéristiques:
- simplicité pour des raisons de mémorisation
- homogénéité pour éviter les risques d'erreurs. En effet si la syntaxe est homogène, l'utilisateur peut développer une automatisation de son comportement en tapant, par exemple "retour chariot" après chaque commande. Si cette règle a des exceptions, ces exceptions seront fatalement des sources d'erreurs. Il faut noter que si l'homogénéisation est facile à atteindre au niveau d'une application, elle l'est plus difficilement d'une application à l'autre et elle nécessite alors une conception globale de la syntaxe du langage d'interaction qui intègre toutes les applications.
La conception d'un langage d'interaction ne se résume pas à ces deux critères. L'objectif d'un langage d'interaction est d'être d'un apprentissage et d'une utilisation faciles pour l'utilisateur.
Pour illustrer ces deux notions, nous nous réferons à une étude faite par Corson (Cor,82) et portant sur la comparaison de deux langages d'interrogation de base de données SQL et QBE.
SQL est un langage d'interrogation classique par mots clés et QBE est un langage dit "graphique" où la syntaxe est allégée au maximun.
Nous donnons un exemple de chacun de ces langages qui traduit la question suivante:
"Trouver le nom des employés qui travaillent dans le département 50 ?"
s'écrit en SQL SELECT NOM
FROM EMP
WHERE DEPT NO = 50
s'écrit en QBE

où seule la deuxième ligne est remplie par l'utilisateur.
Les études évaluatives de SQL montrent que, tant en ce qui concerne l'apprentissage que l'utilisation effective du langage, les programmeurs réalisent de meilleures performances que les non-programmeurs.
Les études comparatives entre SQL et QBE dans les mêmes conditions d'apprentissage de procédures et de test montrent que QBE:
- requiert moins de temps d'apprentissage
- nécessite moins de temps pour les tests
- permet une plus grande exactitude dans l'établissement des requêtes
- provoque un meilleur niveau de confiance.
On peut supposer que la supériorité ergonomique de QBE est essentiellement due à la structure tabulaire préexistante sur l'écran et qui fournit à l'utilisateur une image de la structure de la base de données lui évitant ainsi la mémorisation de la structure de cette base. On peut remarquer ainsi que QBE n'utilise que très peu de mots-clés, ce qui permet d'éviter des confusions avec le langage naturel, comme pour les ET/OU de SQL.
Pour conclure cette étude de l'interrogation des bases de données, nous devons noter que les difficultés d'apprentissage et d'utilisation ne sont pas dues qu'à des problèmes de présentation et de langage d'interaction. Les difficultés peuvent être liées à la compréhension de la question en langage naturel ou au problème de la transposition par rapport à une structure de données prédéfinie. On remarque aussi un certains nombre d'erreurs liées à l'utilisation du ET/OU logique qui n'a pas la même signification que le et/ou du langage naturel et aussi une difficulté à employer des quantificateurs (25% des erreurs des utilisateurs dans QBE).
Ainsi, sans réduire le problème de l'interrogation des bases de données à celle du choix du langage d'interaction et de présentation, nous voyons que celui-ci a une importance non négligeable sur la facilité d'apprentissage et la minimisation des erreurs.
Un des rôles essentiels des dispositifs d'entrée à part la saisie proprement dite est de permettre la distinction entre commandes et données du point de vue de l'informaticien.
La saisie des données en informatique des organisations ne pose pas de problèmes particuliers car elle se fait obligatoirement par l'intermédiaire des touches alphanumériques du clavier. L'entrée vocale et la désignation directe sur écran sont fort peu utilisées et utiles.
La saisie des commandes offre une plus grande variété:
- frappe au clavier du mot entier ou abrégé désignant la commande
- frappe de touches spécialisées ou touches fonctions
- frappe d'une association de touches, en général une touche spécialisée en même temps qu'une touche banalisée
- désignation par positionnement du curseur et validation, soit par les touches directionnelles du clavier, soit par la souris
- désignation directe sur l'écran par l'intermédiaire d'un light pen ou du doigt
Ces différents modes de saisie ne sont pas équivalents du point de vue de l'utilisateur. Les deux derniers cités sont les moins coûteux sur le plan de la mémorisation; ce peut être le cas aussi de la saisie des premiers caractères de la commande si celle-ci est visualisée sur l'écran. Ces modes de saisie sont donc à préconiser dans le cas d'utilisateurs novices ou intermittents.
Par contre les touches spécialisées peuvent s'avérer très efficace pour des personnes utilisant intensivement le logiciel et habituées à l'usage du clavier.
L'association de touches, très utilisée par les informaticiens, est le dispositif d'entrée le plus complexe pour l'utilisateur; il est difficile à mémoriser et à manipuler et entraîne ainsi de fréquentes erreurs.
Le travail interactif avec l'ordinateur se déroulant principalement devant un écran, il nous a semblé important de savoir si l'utilisateur avait des stratégies d'exploration d'écran qui nous permettraient de concevoir des présentations adaptées.
Nous nous sommes rendus compte qu'il faut distinguer deux catégories de cas, selon que l'utilisateur explore l'ensemble de l'écran pour découvrir ce qu'il cherche ou qu'il recherche de manière sélective une information qu'il pense être à une certaine place. Nous parlerons dans le premier cas de "recherche systématique" et dans le second cas de "recherche sélective".
Pour ce type d'exploration d'écran, nous nous réfèrons à une expérience faite par Sperandio et Gonju (Spe,83) qui porte sur l'exploration visuelle de tableaux numériques où l'opérateur cherche un nombre donné sans connaître sa localisation.
La première constatation que l'on peut faire est que, dans les pays occidentaux, la lecture d'un texte apparaissant sur un support quelconque s'effectue a priori dans le sens gauche/droite et haut/bas.
Dans le cas des tableaux, l'expérience montre que la stratégie d'exploration est au départ une stratégie par ligne (gauche/droite) et évolue ensuite par colonne (haut/bas) l'inverse. On note également une diminution progressive des durées de fixation et, corrélativement, une diminution du nombre de fixations. La stratégie d'exploration par colonne est adoptée car elle est la plus économique en ce sens qu'elle permet plus facilement une fixation sur le premier chiffre du nombre.
Cette expérience tend à montrer que ce que l'utilisateur voit le mieux est ce qui est situé dans le coin supérieur gauche ou dans la zone centrale. Par contre les nombres situés en extrémité de ligne ou de colonne ont une moins grande probabilité d'être perçus avec précision, d'autant plus que les écrans bombés distordent plus ou moins l'image sur les bords.
Avant de conclure sur la recherche systématique, nous voudrions relativiser les résultats précédents par le fait que les expériences portent exclusivement sur des tableaux de chiffres.
D'autres études menées par des publicitaires ont montré que dans le cas d'une exploration rapide d'un support et d'une information quelconque, la stratégie d'exploration de l'usager fait un "z" : c'est à dire que l'oeil part du coin supérieur gauche, balaye une ligne de gauche à droite traverse l'image en diagonale du coin supérieur droit vers le coin inférieur gauche et balaye la dernière ligne de gauche à droite. Ce résultat n'a de sens que pour des utilisateurs qui ne connaissent pas la structure de l'information qu'ils vont rencontrer sur l'écran et qui ont par contre des contraintes de temps.
Ces résultats ne sont pas parfaitement concordants puisqu'ils ne portent pas sur le même protocole d'expériences, mais ils ont en commun trois éléments :
- l'exploration commence par le coin supérieur gauche
- la zone centrale est parcourue systématiquement (en partant du coin supérieur gauche ou droit)
- l'extrémité gauche ou droite des images est mal vue.
Nous pouvons déduire de ces éléments que pour des utilisateurs novices ou occasionnels de l'informatique, les informations importantes (qui doivent être nécessairement lues) doivent commencer dans le coin supérieur gauche ou se situer dans la zone centrale.
Lorsque l'écran affiche une structure de l'information qui est connue de l'utilisateur et que celui-ci perçoit cette information dans un certain but, la recherche de l'information est sélective et non plus systématique; autrement dit, la saisie de l'information est gouvernée par les processus cognitifs . De manière plus précise, la saisie visuelle dépend moins des caractéristiques physiques du stimulus (intensité, taille, localisation, formes) que des stratégies opératoires de l'utilisateur, qui sont déterminées par les caractéristiques de la tâche et le degré d'expérience des utilisateurs.
Nous illustrons ces idées par une étude faite par Bouju et Sperandio (Bou,79) et portant sur les contrôleurs aériens.
L'objectif de cette étude était de voir si il y avait des différences de stratégie d'exploration visuelle selon le degré d'expérience des contrôleurs et selon l'augmentation du trafic aérien.
En règle générale, quand le trafic augmente on observe une prise d'information plus sélective, c'est-à-dire centrée sur les informations jugées pertinentes par les contrôleurs pour leur décision; les informations jugées pertinentes diffèrent selon le degré d'expérience des utilisateurs. Ce phènomène s'accompagne d'une augmentation de la durée moyenne de fixation sur les éléments pertinents.
Dans tous les cas, on n'observe pas une exploration systématique des informations, mais une fixation sélective sur les points où le contrôleur sait qu'il va trouver l'information pertinente.
Quand le volume du trafic augmente, le contôleur expérimenté choisit un mode de régulation plus standardisé, c'est-à-dire plus économique pour lui.
Si on veut transposer ces résultats dans le cadre de l'informatique des organisations, on peut dire que l'utilisateur expérimenté ne va pas explorer l'ensemble de l'écran, mais uniquement les points qui lui semblent pertinents et qui pourraient ainsi être regroupés dans les zones observées le plus spontanément.
On remarque ainsi qu'en cas de surcharge de travail, l'utilisateur s'achemine vers une standardisation des procédures d'exploration. On facilitera le travail de l'utilisateur si, d'une application à l'autre, on lui fournit les informations de même nature dans les mêmes zones (standardisation des emplacements des zones de menus, messages d'erreurs, etc....).
Le concept d'homogénéité permettant d'acquérir des automatismes qui accélérent la prise d'information, prime sur celui d'emplacement; peu importe que la barre de menu soit sur la ligne du haut ou du bas pourvu qu'elle soit toujours à la même place dans toutes les applications.
Nous présentons maintenant les différences de recommandations entre présentation des données et présentation des commandes.
La présentation des données peut se faire de deux manières différentes: par question/réponse ou par remplissage de formes.
Le mode question/réponse ne donne aucune latitude à l'utilisateur, il ne doit donc être utilisé que dans le cas où le guidage total par l'ordinateur s'impose.
Le remplissage de formes est plus souple car il peut permettre à l'utilisateur d'entrer les données dans un ordre différent de celui proposé (ce qui est trés intéressant dans le cas d'un dialogue avec un client) mais aussi d'imposer un ordre dans le cas de saisie de formulaires.
Dans ce cas (saisie de formulaires), il est impératif que l'ordre de présentation des données soit le même que celui du formulaire.
La présentation des commandes peut ne pas exister dans le cas d'utilisation d'un langage de commande; cette absence de présentation ne peut convenir qu'à un public très spécialisé utilisant fréquemment ces logiciels.
Dans le cas usuel la présentation des commandes se fait sous forme d'un menu qui peut présenter les variabilités suivantes:
- visualisation uniquement à la demande (touche "aide")
- barre de menu affichée en permanence
- menu déroulant dont seul l'en-tête est visualisée, le reste apparaissant à la demande
- menu glissant qui permet de visualiser une liste de commandes plus grande que la place disponible
- menu dynamique qui signale à l'utilisateur les commandes disponibles à un moment donné de l'interaction (au moyen d'une surbrillance par exemple)
L'ensemble de ces présentations par menu demande peu de mémorisation de la part des utilisateurs et est donc particulièrement adapté à tous les utilisateurs novices et intermittents.
Selon les types de logiciel de gestion d'écran (voir chapître 4), la présentation des données et des commandes peut se faire sous la forme de monofenêtre ou de multifenêtre ; la présentation monofenêtre est la plus répandue car la plus ancienne, mais la présentation multifenêtre est en plein développement.
L'avantage essentiel de cette dernière est de permettre la visualisation de plusieurs opérations simultanément, ce qui est d'une utilité certaine pour l'utilisateur dans le cas d'interruption et de transfert d'informations entre opérations. On peut même dire que ces deux types d'opérations ne sont de fait praticables qu'avec le multifenêtrage.
Le découpage de l'écran en fenêtres et le recouvrement partiel ou total peut être géré automatiquement par le logiciel ou être laissé à l'initiative de l'utilisateur; il n'y a pas de recommandations ergonomiques à ce sujet car cela dépend du type d'application et du type d'utilisateur.
Ici aussi, une expérimentation sur prototype peut s'avérer utile.
La question qui se pose est la suivante : "Quel est le temps de réponse idéal?"
- immédiat, répondent Sperandio et Volleau (Spe,80) ;
- pas trop rapide, dit Wisner (Wis, 79), car cela crée une surcharge mentale par accélération des processus cognitifs.
Pour tenter de répondre plus précisément, nous pouvons nous référer à deux paramètres importants :
- dans une conversation entre deux personnes, le temps de réponse maximun est de l'ordre de deux secondes (étant bien entendu que la réponse peut être verbale ou représentée par un geste, un mouvement facial ou autre). D'après les observations menées, deux secondes semble bien correspondre à un seuil au-delà duquel l'individu a l'impression d'attendre ;
- par ailleurs, nous avons vu que les informations qui entrent ou qui sortent du cerveau humain transitent par une mémoire à court terme pendant 2 à 6 secondes au maximun.
En conséquence, si, en cours de travail, nous sommes interrompus par un événement extérieur, nous risquons d'effacer l'information de la mémoire à court terme.
En résumé, il est gênant d'être interrompu pendant la phase de mémorisation et il est pénible de devoir conserver trop longtemps l'information dans la mémoire à court terme, ce qui est le cas si le temps de réponse est supérieur à 4 secondes.
Par contre, un temps de réponse plus long pour une opération qui ne demande pas de mémorisation (l'impression, fin de travail), ne pose pas de problème à condition toutefois que l'utilisateur soit averti par un message affiché sur l'écran. Si le temps de réponse est vraiment trop long, il faut afficher ce temps pour que l'utilisateur puisse faire éventuellement autre chose en attendant. Sinon, cela peut provoquer de l'anxiété car il n'est pas en mesure de savoir si ce temps d'attente provient de contraintes techniques ou d'une erreur de sa part. Toujours pour la même raison d'anxiété, il faut éviter les temps de réponse trop variables.
Nous arrivons donc aux résultats suivants:
- moins de 2 secondes : temps de réponse idéal ;
- 2 à 4 secondes : impression d'attente, peu gênante pour la mémoire à court terme,
- plus de 4 secondes : trop long si le dialogue nécessite une mémorisation à court terme et s'il n'y a pas de messages affichés à l'écran.
On distingue deux types d'erreur:
- les erreurs d'exécution qui proviennent du fait que l'on a tapé par inadvertance sur une autre touche que celle désirée; ce type d'erreur est souvent facilement détectable et rectifiable;
- les erreurs d'intention qui correspondent à une mauvaise interprétation du sens des commandes ou de la signification des procédures; ces erreurs peuvent n'être détectées que tardivement et leurs rectifications demandent un apprentissage de la part de l'utilisateur.
Pour le signalement des erreurs, il y a unanimité sur les éléments suivants:
- les erreurs doivent être signalées immédiatement ou le plus rapidement possible à cause de la "volatilité" de la mémoire à court terme,
- les messages d'erreur doivent être explicites et décrire, si possible, la cause de l'erreur,
- les messages d'erreur doivent être présentés toujours sous la même forme pour des raisons d'homogénéité et donc d'optimisation de la recherche sélective.
Par contre, il y a plusieurs possibilités pour l'emplacement proprement dit du message d'erreur :
- à côté de l'erreur, on est sûr que l'utilisateur verra le message mais il peut ne pas y avoir assez de place, sauf si l'on utilise une fenêtre en surimpression (logiciel de multifenêtrage)
- dans une zone spéciale on peut ne pas remarquer le message d'erreur, ce qui peut amener à rajouter des marques spéciales comme un clignotement du curseur ou de la zone, un signal sonore, une inversion vidéo...
Pour la correction des erreurs, l'utilisateur doit pouvoir revenir aisément à l'opération ou à la ligne où se situe l'erreur et il doit pouvoir annuler éventuellement en totalité ou en partie le travail qu'il a fait depuis lors.
Les possibilités de correction d'erreur posent des problèmes souvent complexes en informatique; ce ne sont pas des paramètres de surface du logiciel, mais des paramètres de la structure profonde que l'on définit lors de la Représentation Conceptuelle, en particulier quand on définit le séquencement des opérations.
Selon Senach (Sen,87), il y a essentiellement deux types de guidage:
- le guidage fonctionnel par description des commandes; ce guidage fournit pour chaque commande sa définition et ses effets, ses conditions d'exécution, ses effets de bord éventuels; ces descriptions peuvent être faites à trois niveaux de détails (résumé, détaillé, catalogue de problèmes)
- le guidage d'utilisation par reconnaissance des plans d'action de l'utilisateur; ce guidage suppose une métaconnaissance sur les différents buts possibles de l'utilisateur, une gestion du contexte de l'interaction (historique des transactions), une gestion du contexte de l'utilisateur (procédures adaptées à un utilisateur donné)
Le guidage fonctionnel est adapté à des utilisateurs expérimentés qui veulent se rappeler la syntaxe et la sémantique d'une commande.
Le guidage d'utilisation convient mieux à des utilisateurs novices ou intermittents car il peut les guider dans la réalisation de leur tâche en leur indiquant l'ensemble des opérations à parcourir en fonction du but qu'ils veulent atteindre.
Nous avons vu que la Représentation Conceptuelle est constituée de deux ensembles de paramètres que nous avons appelés :
- les paramètres constants,
- les paramètres variables propres à une application particulière.
Ces deux ensembles ne sont pas du tout de même nature.
Les paramètres constants sont à mettre en oeuvre pour faciliter le travail de l'utilisateur quel que soit le type de tâches qu'il a à accomplir ce qui nécessiste donc la conception d'outils généraux.
Les paramètres variables sont des éléments (traitement et données) issus de l'analyse du travail, spécifiques à chaque application.
A cause de cette différence, nous examinerons séparement la traduction de ces paramètres en R.E.

La définition des paramètres constants est totalement indépendante de celle des paramètres variables, mais l'interface résultante "vue" par l'utilisateur (R.E) sera la conjonction de ces deux ensembles d'éléments.
Dans ce paragraphe, nous décrivons tous les éléments qui ne sont pas liés à une application particulière; il s'agit, d'une part de la traduction des paramètres constants provenant de la Représentation Conceptuelle, d'autre part des options standard qui doivent être prises pour homogénéiser toutes les applications.
Nous avons défini trois types de paramètres constants qui sont ceux :
- d'aide au travail
- d'aide à l'apprentissage
- d'évolution.
Pour l'aide au travail, nous avons défini les éléments suivants :
- les possibilités d'interrompre à tout moment une tâche pour aller en exécuter une autre
- les possibilités de quitter le travail à n'importe quel moment
- les possibilités de différer le travail en cours
- la possibilité de transférer les données d'une tâche à l'autre.
- l'annulation pour la gestion des erreurs
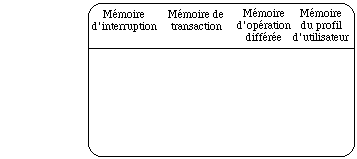
- la mémorisation de l'activité de l'utilisateur (gestion du contexte) qui comprend quatre aspects (opérations interrompues, opérations différées, traces du travail, paramètres propres à l'utilisateur).
L'aide à l'apprentissage concerne le guidage fonctionnel et le guidage d'utilisation.
Les possibilités d'évolution concernent les éléments de la représentation conceptuelle que l'utilisateur peut modifier lui-même.
Ces paramètres sont qualifiés de constants en ce sens qu'ils sont utiles quelle que soit l'application traitée. Aussi, serait-il logique qu'ils soient intégrés dans un logiciel de base sur lequel on pourrait greffer les éléments propres à une application particulière.
C'est ce qui est fait, partiellement, avec les logiciels de multifenêtrage que nous décrivons au chapitre 4. Ils gérent automatiquement l'interruption et le transfert de données entre opérations, les autres paramètres devant être programmés.
Nous pouvons constater que ces paramètres constants permettent de prendre en compte les recommandations ergonomiques concernant le séquencement des opérations, le guidage et partiellement la correction d'erreurs.
La question que nous devons résoudre ici est la suivante:
"Comment présenter ces possibilités à l'utilisateur au niveau de l'interface?"
La règle qui s'impose en priorité est celle de l'homogénéité ; ces paramètres étant communs à toutes les appplications doivent être présentés exactement de la même façon quelle que soit l'application, c'est-à-dire qu'ils doivent:
- recevoir la même dénomination
- être présentés visuellement sur l'écran de la même manière
- être sélectionnés avec le même dispositif d'entrée.
Nous détaillons ci-dessous les critères que l'on peut mettre en oeuvre pour traduire les paramètres constants dans une Représentation Externe adaptée aux utilisateurs.
A titre d'illustration, nous présentons deux possibilités selon que l'on dispose d'un logiciel de gestion d'écran mono ou multifenêtre.
Dans le cas où nous mettons en oeuvre l'ensemble des possibilités énumérées précédemment ou, du moins, une partie importante d'entre elles, il est nécessaire de procéder à un regroupement en sous-ensembles afin de ne pas surcharger l'écran.
Le critère de regroupement essentiel est la fréquence d'utilisation.
A titre d'exemple, l'ensemble des commandes standard est subdivisé en quatre sous-ensembles selon leur fréquence d'utilisation; cette subdivision est indépendante du type de logiciel de gestion d'écran:
- le premier sous-ensemble concerne l'aide à l'utilisation avec les commandes Interrompre Différer Quitter Annuler Copier Insérer
- le second sous-ensemble concerne la mémorisation avec la commande Mémoire à un premier niveau et les commandes Interruption Transaction Différé Utilisateur au second niveau
- le troisième sous-ensemble concerne l'aide à l'apprentissage avec la commande Guidage au premier niveau et les commandes Buts et Commandes au deuxième niveau
- le quatrième sous-ensemble concerne les possibilités d'évolution avec la commande Evolution au premier niveau et les commandes Procédure Opération Statut Déclenchement Précédence au deuxième niveau.
Le choix de la dénomination des commandes standard comporte un aspect arbitraire, car on ne peut se référer à aucun vocabulaire de spécialiste; les commandes standard correspondent à des opérations spécifiques de l'interaction homme-machine qui n'ont pas d'équivalent dans le travail manuel.
Mais, on peut s'inspirer des principes suivants:
- pour éliminer l'indétermination syntaxique, il y a lieu de nommer toutes les commandes sous la même forme syntaxique; on prendra soit la forme verbale soit la forme nominale. La pratique des informaticiens consiste plutôt à prendre la forme verbale, sans que cette pratique soit confirmée ou infirmée par des tests d'ergonomie;
- la dénomination de la commande doit refléter le point de vue des utilisateurs et non des informaticiens.Par exemple, la même commande s'appellera "consulter thesaurus" du point de vue de l'utilisateur et "afficher thesaurus" du point de vue de l'informaticien.
En cas d'ambiguïté, il est utile de procéder à des tests d'apprentissage et de mémorisation.
La présentation des commandes standard à l'écran est guidée par deux critères:
- ne pas surcharger l'écran de commandes inutiles ou utilisées peu fréquemment,
- rester au maximum homogéne entre toutes les applications
Exemple avec logiciel monofenêtre:
Afin de ne pas surcharger l'écran, nous avons décidé que le menu standard n'utiliserait qu'une ligne ce qui,dans le cas usuel, correspond à 80 caractères. Ce choix nous oblige à créer deux niveaux de commandes où le premier niveau est affiché en permanence dans la ligne menu; le deuxième niveau n'apparaissant qu'à la demande.
Pour minimiser les manipulations, nous mettons dans le deuxième niveau les commandes utilisées plus rarement.
Nous aurons donc en permanence la barre de menu suivante:

Nous choisissons de disposer cette barre sur la première ligne de l'écran; nous aurions pu décider de la mettre sur la dernière ligne, l'essentiel étant de rester homogène sur l'ensemble des applications.
Si l'utilisateur sélectionne une des six premières commandes, il y aura exécution immédiate alors que les trois dernières commandes donneront lieu à l'affichage d'une autre barre de menu au même emplacement.
La commmande Mémoire affichera la barre suivante:
Exemple avec logiciel de multifenêtrage:
Le multifenêtrage permet d'utiliser un menu déroulant c'est à dire un menu qui apparaît dans une fenêtre en surimpression uniquement pendant le temps souhaité par l'utilisateur.L'avantage de ce type de menu réside dans le fait que l'on ne fait apparaître que ce qui concerne l'utilisateur et ceci sans surcharger l'écran.
Cela suppose une structuration des commandes en deux niveaux; les commandes du premier niveau étant affiché en permanence dans une barre de menu; les commandes du second niveau associées à chaque commande du premier niveau n'apparaissant qu'à la demande dans des menus déroulants.
Au premier niveau, nous indiquons les quatre sous-ensembles décrits dans le premier exemple sous la forme d'une barre de menu qui occupe la première ligne de l'écran, ce qui permet au menu déroulant d'apparaître au-dessous de chaque commande; si l'utilisateur sélectionne la commande Aide, il obtiendra:
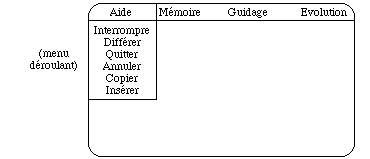
Et il obtiendrait de la même manière les commandes de deuxième niveau associées à Mémoire Guidage et Evolution.
Pour sélectionner les commandes, on peut utiliser diverses possibilités:
- positionner le curseur sur la commande au moyen des touches-fonctions de déplacement (ou d'une souris,...) puis valider par une touche-fonction. Cette possibilité est intéressante pour les utilisateurs novices ou intermittents car elle demande peu d'effort de mémorisation;
- taper la (ou les) première lettre de la commande en association avec une autre touche indiquant que l'on est en mode saisie de commande. Ce mode de désignation est plus complexe à mémoriser que le précédent; mais il peut être utilisé par des non-spécialistes, si les commandes et leurs abréviations sont affichées en entier et en permanence sur l'écran. Dans le cas contraire, il faut le réserver à des spécialistes assidus;
- utiliser des touches-fonctions associées à chaque commande. Cette possibilité est très efficace pour des utilisateurs expérimentés.
Exemple:
Nous choisissons d'implémenter deux possibilités ; la première citée pour les utilisateurs novices et la dernière pour les utilisateurs expérimentés.
Pour des utilisateurs novices ou intermittents, la sélection la plus simple d'une commande se fait au moyen de la souris (ou de toute autre désignation directe); quand l'utilisateur positionne avec la souris le curseur sur la commande Aide le menu ci-dessus apparaît tant que l'utilisateur appuie sur le bouton de la souris; il ne lui reste plus qu'à faire glisser le curseur jusqu'à la commande désirée et à relacher le bouton de la souris sur cette position pour que cette commande soit sélectionnée. Cette manoeuvre est en fait plus difficile à décrire par écrit qu'à exécuter physiquement!
Pour des utilisateurs plus expérimentés qui n'ont pas besoin de visualiser le menu déroulant, il est plus rapide de taper sur une touche-fonction .
On peut détecter deux types d'erreur, soit l'utilisateur sélectionne une commande qui n'existe pas, soit il sélectionne une commande qui existe mais qui ne peut être activée à ce moment là (c'est le cas de la commande Copier qui ne peut être sélectionnée deux fois de suite sans risque d'ambiguïté).
Dans le premier cas (commande inexistante), on fait apparaître un message d'erreur dans une zone de l'écran spécialisée à cet effet selon les options définies dans l'écran standard (voir paragraphe suivant).
Avec le multifenêtrage, la visualisation des messages d'erreur peut se faire dans une fenêtre en surimpression ce qui a l'avantage d'être très bien perçu par l'utilisateur.
Dans le second cas, on peut procéder de la même manière mais il est plus efficace d'indiquer également sur les commandes elle-mêmes celles qui sont activables et celles qui ne le sont pas afin de minimiser ce type d'erreur; ceci correspond à la notion de menu dynamique, c'est-à-dire au signalement a priori des commandes possibles à un moment donné.
Pour présenter ce menu dynamique, on fait ressortir visuellement (surbrillance, inversion vidéo,...) les commandes activables à un moment donné par rapport aux commandes non activables; on peut également faire disparaitre de l'écran les commandes non activables, mais cette façon de procéder est moins judicieuse car elle ne préserve pas l'homogénéité de la présentation.
Avant de décrire une opération et une procédure particulière, il est impératif de déterminer une disposition standard de l'écran qui servira de cadre pour l'ensemble des applications.
Les critères de disposition doivent s'inspirer des résultats d'ergonomie sur la recherche systématique et sélective; nous avons vu qu'un novice va balayer l'écran en "z" , alors qu'un expérimenté consultera directement la zone qui l'intéresse (si l'écran est standard, cette stratégie devient très efficace).
Aussi, on peut en déduire que, si on veut que les zones de menu (dans la mesure où elles existent) soient vues par des utilisateurs novices, il faut les mettre sur la première ou la dernière ligne de l'écran; cette option ne constitue pas une gêne pour les utilisateurs expérimentés dans la mesure où ils ne consulteront cette zone que s'ils en ont besoin.
Un autre critère à utiliser est la non surcharge de l'écran; ce critère peut être en contradiction avec les autres car il peut amener à ne pas spécialiser des zones d'écran, de manière à libérer tout l'écran pour la zone de dialogue dans le cas d'opérations à très forte densité d'informations.
Les possibilités de disposition sont bien sûr différentes selon que nous disposons ou non d'un logiciel de multifenêtrage; nous examinons à titre d'exemple les deux possibilités.
Exemple de disposition standard monofenêtre :
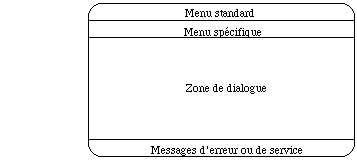
Nous spécialisons quatre zones:
- les zones de menu spécifique et standard occupent les deux premières lignes de l'écran
- la zone de message d'erreur et de service occupe la dernière ligne
- la zone de dialogue utilisée dans chaque opération occupe tout le reste de l'écran.
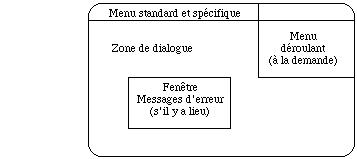
Exemple de disposition standard multifenêtre :
- les zones de menu spécifique et standard n'occupent que la première ligne de l'écran car l'utilisation de menu déroulant permet de regrouper plus fortement les commandes sans gêne pour l'utilisateur
- la zone de message d'erreur et de service n'existe pas en permanence; elle sera éditée dans une fenêtre en surimpression qui ne sera affichée qu'en cas de message
- la zone de dialogue occupe le reste de l'écran.
Une partie de la syntaxe du langage d'interrogation a un caractère général et doit donc être déterminé à ce niveau de manière à être homogéne sur l'ensemble des applications. Il s'agit:
- du mode de sélection des commandes (standard ou spécifiques)
- de la validation des données ou des écrans.
Le contenu des messages de service est dépendant du contenu d'une application particulière mais il existe un message de service à caractère général, c'est celui concernant le temps de réponse.
En effet, le temps de réponse n'est pas connu à ce stade de la conception puisqu'il dépend de la Représentation Interne de l'application, mais nous avons vu qu'au-delà de 2 secondes l'utilisateur a l'impression d'attendre et qu'au delà de 4 secondes, il est indispensable de lui signaler par un message que la procédure se déroule normalement.
Le contenu et la forme du ou des messages concernant le temps de réponse doivent être déterminés à ce stade car ils sont indépendants du contenu de l'application.
Quand l'étape de la Représentation Conceptuelle est finie, nous disposons, pour chaque but d'un poste de travail, de spécifications compléèes concernant la structure de données et la structure de traitement des opérations de la procédure.
Pour chaque opération interactive, nous connaissons:
- la liste de ses actions
- la liste de ses entrées
- la liste de ses sorties
- ses pré-requis
- son déclenchement
Pour chaque procédure, nous avons:
- la liste des opérations activables
- les précédences entre ces opérations.
Au niveau de la Représentation Externe, il nous reste à définir pour chaque opération interactive:
- la disposition du ou des écrans
- le vocabulaire des données
- le contenu des messages d'erreur, de service ou de guidage
- la syntaxe
- les dispositifs d'entrée.
Pour l'ensemble de la procédure, nous devons définir:
- les noms des commandes activant les opérations
- la hiérarchie du menu
- la présentation du menu
- la syntaxe et les dispositifs d'entrée
- les messages d'erreur et de guidage.
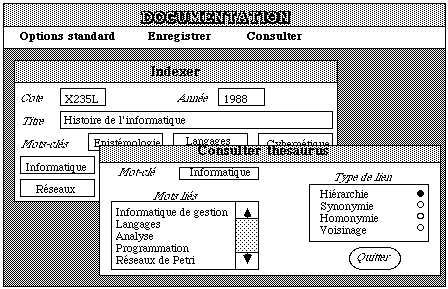
Nous illustrons cette démarche sur un exemple qui reprend celui de la documentation développé dans le chapitre deux. Nous décrivons l'opération "enregistrement des bases du document" et la procédure minimale d'un poste de documentation.
Vocabulaire
Pour la détermination du vocabulaire des données, il n'existe qu'un seul critère qui est celui d'utiliser le vocabulaire des spécialistes de la tâche (ou le vocabulaire courant pour les applications "grand public").
Dans les cas (rares) où il y a création de données qui n'existent pas dans les tâches actuelles, il est nécessaire de procéder à des tests d'apprentissage et de mémorisation pour ces nouveaux noms.
Exemple:
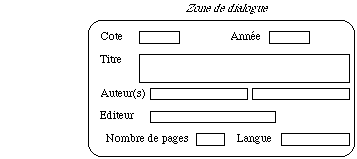
Pour décrire les données qui permettent au documentaliste d'enregistrer un document nous choisissons le vocabulaire déjà utilisé par le documentaliste qui est: COTE, AUTEUR, TITRE, EDITEUR, ANNEE, NOMBRE DE PAGES, LANGUE.
L'indication de fin de saisie de données doit être faite par le même moyen sur l'ensemble de l'application.
Le même principe doit être appliqué pour la validation de l'ensemble de l'écran.
Si l'opération correspond à un document sur papier ou à un écran existant déjà, il faut ,dans la mesure où ces documents ou ces écrans sont adaptés aux nécessités de la tâche, s'en inspirer fortement compte-tenu des nouvelles contraintes techniques.
Dans les autres cas, il faut rechercher la ou les logiques d'utilisation de cette opération de manière à présenter les données dans l'ordre de la logique d'utilisation la plus courante en prévoyant éventuellement des possibilités de variantes dans l'ordre de remplissage, par exemple, s'il y a lieu.
Exemple:
Nous reproduisons sur l'écran l'ordre et la disposition spatiale contenu dans une fiche documentation manuelle car les documentalistes y sont habitués et surtout parce que les systèmes manuels et automatiques vont continuer à coexister, ce qui donne:
Pour une opération, le dispositif d'entrée concerne la saisie des données et l'enchaînement des différentes zones de saisie.
Les données peuvent être saisies au clavier, ou sélectionnés sur une liste affichée par le logiciel, ou en provenance d'une autre opération.
Le premier cas ne pose pas de probléme; dans les deux autres cas, il faut veiller au fait que les modes de désignation soient homogènes sur l'ensemble de l'application.
Le mode d'enchaînement des zones de saisie est déterminé dans la Représentation Conceptuelle; s'il est à l'initiative de l'ordinateur , cela se traduit par un positionnement automatique du curseur; s'il est à l'initiative de l'utilisateur, il faut prévoir un mode de désignation d'une zone par l'utilisateur. Le plus simple et le plus efficace est la désignation directe (souris, light pen,...) ou à la rigueur les touches-fonction de déplacement de curseur.
Exemple:
Les zones sont enchainées automatiquement car cet ordre correspond aux habitudes des documentalistes et tous les renseignements sont groupés sur un même document. Le choix des touches-fonctions pour la syntaxe est motivé par le fait qu'il y a beaucoup de saisie au clavier et que les documentalistes sont trés habitués à utiliser un clavier.
Nous devons déterminer l'ensemble des erreurs que l'utilisateur peut commettre et surtout que le logiciel peut détecter afin de prévoir les messages d'erreurs correspondants. Chaque message d'erreur doit être le plus explicite possible et indiquer le type de contrôle qui est effectué.
Exemple:
Sur la "Cote" il peut y avoir deux types d'erreur:
- une erreur de vraisemblance si l'utilisateur tape une cote incompatible avec la composition prévue (deux lettres suivies au maximum de six chiffres) auquel cas le message sera "mauvaise composition de la cote";
- une erreur de concordance si la cote correspond à une cote existant déjà ce qui est impossible puisque cette opération a pour but de permettre l'enregistrement de nouveaux livres; le message d'erreur étant "cote déjà attribuée".
Sur l' "Année" il peut y avoir un contrôle de vraisemblance sur une fourchette minimum/maximum avec le message "erreur sur la date".
Sur l' "Auteur" il ne peut pas y avoir de vérifications.
Sur l' "Editeur", il y a contrôle de concordance avecune liste d'éditeur et le message est donc "éditeur non enregistré".
Sur le "Nombre de pages", il y a un contrôle de vraisemblance sur les chiffres avec en réponse le message "le nombre de pages doit être numérique".
Sur la "Langue", il y a un contrôle de concordance par rapport à une liste de langues avec le message "langue non enregistrée".
Nous devons déterminer l'ensemble des noms de commande correspondant à chaque opération. Là aussi, il faut au maximum adopter le vocabulaire employé par les spécialistes de la tâche, mais ce n'est pas toujours possible quand des opérations automatisées ne correspondent pas à des opérations manuelles.
Dans ce cas, on s'inspirera des deux principes développés pour la dénominations des commandes standard (forme verbale ou nominale, dénomination du point de vue de l'utilisateur); en cas d'ambiguïté on procédera à une expérimentation.
Exemple:
Nous donnons ci-dessous la liste des différentes opérations de la procédure minimale d'un poste de documentation et la liste correspondante des noms de commande.

L'opération "Enregistrement mots-clés du document" n'a pas de nom de commande correspondant car elle correspond à un déclenchement automatique dans la procédure minimale et ne peut donc être déclenchée par l'utilisateur.
Dans le cas général, l'ensemble des commandes d'une application interactive est trop important pour pouvoir être présenté à l'utilisateur sous la forme d'une liste unique. Aussi, on subdivise l'ensemble des commandes de manière à obtenir une stucture arborescente ou hiérarchisée; l'utilisateur doit alors parcourir cette arborescence pour activer les commandes utiles à son travail.
Cette structure hiérarchique du menu ne doit en aucun cas être faite par rapport à la logique des traitements informatiques mais par rapport à la logique d'utilisation des utilisateurs. Cette logique d'utilisation a été déterminé au niveau de la Représentation Conceptuelle quand on décompose le travail à effectuer en buts, sous-buts,..., opérations.
C'est cette structuration qui doit être reprise ici; les buts correspondent au niveau un de la structure arborescente, les sous-buts au niveau deux et les opérations au dernier niveau.
Exemple:
Comme nous l'avons vu au chapitre 2, à la suite d'une étude sur la logique d'utilisation des documentalistes, on a constaté que le but de la procédure qui est de gérer les documents se subdivise en deux sous-buts: "enregistrer document" et "consulter document".
Les commandes ci-dessus sont donc regroupées en deux sous-ensembles:
- le premier sous-ensemble nommé "Enregistrer" regroupe toutes les commandes permettant d'atteindre ce sous-but, soit Indexer, Créer mots clés, Lier mots clés, Consulter thesaurus.
- le second sous-ensemble nommé "Consulter" regroupe Consulter thesaurus, Chercher document, Imprimer.
Comme nous l'avons déjà remarqué, dans ce découpage en logique d'utilisation, certaines commandes (ici, consulter thesaurus) peuvent apparaître dans plusieurs sous-menus puisque l'objectif est de minimiser les manipulations de l'utilisateur.
Le menu peut être affiché en permanence ou seulement à la demande de l'utilisateur; l'affichage permanent est plus favorable aux utilisateurs novices ou intermittents alors que l'affichage à la demande, s'il est utilisé, doit être réservé aux utilisateurs expérimentés.
Dans le cas d'affichage permanent, la ligne où est affichée le menu a un contenu évolutif selon la demande de l'utilisateur; au premier niveau, elle contient la liste des buts et au dernier niveau, la liste des opérations.
Avec un logiciel de multifenêtrage, on peut avoir une variante qui consiste à mettre la liste des opérations dans un menu déroulant.
Exemple avec logiciel monofenêtre:
Dans la barre de menu initiale (au premier niveau), on affiche les sous-buts:
Enregistrer et Consulter.
Quand l'utilisateur sélectionne un but, la barre de menu initiale est remplacée par l'ensemble des commandes dépendantes de ce but; par exemple, si l'utilisateur sélectionne "Enregistrer", on affiche:
Indexer, Créer mots-clés, Lier mots-clés, Consulter thesaurus.
L'utilisateur dispose ainsi de l'ensemble des commandes lui permettant de réaliser un enregistrement sans avoir à revenir au premier niveau .
Exemple avec logiciel de multifenêtrage:
La barre de menu initiale (contenant les buts) reste affichée en permanence et la liste des opérations dépendante d'un but apparaît à la demande de l'utilisateur dans un menu déroulant comme nous l'indiquons dans le schéma suivant:

Comme pour la sélection des commandes standard, on peut utiliser le clavier avec la touche "mode commande" et la frappe d'une abréviation de la commande désirée ou la souris en positionnant le curseur sur la commande et en cliquant ou une touche-fonction.
Exemple:
On réserve les touches fonctions aux commandes standard.
Pour les commandes spécifiques à l'application, on offre deux types de mode de sélection laissé au choix de l'utilisateur; la désignation directe par la souris et la combinaison d'une touche commande et d'une abréviation de la commande.
Comme pour le menu standard, nous avons deux types d'erreur:
- l'erreur de concordance, si la lettre tapée ne correspond pas à une commande; il est important de remarquer qu'il ne peut pas y avoir d'erreur si la sélection se fait par cliquage de la souris.
- l'erreur d'utilisation si l'utilisateur veut activer une commande existante mais non activable à ce stade de la transaction.
Exemple:
Pour l'erreur de concordance, le message sera "commande inconnu, veuillez la retaper".
Le probléme de l'erreur d'utilisation ne se pose pas dans cet exemple car, dans la procédure minimale du poste de documentation, il n'y a qu'une précédence qui est à déclenchement automatique. Par contre le cas pourrait se poser dans une autre procédure effective.
Il est important ici de prévoir le contenu des messages qui serviront de guide à l'utilisateur.
Pour le guidage fonctionnel, on fournira pour chaque commande, un résumé décrivant le rôle et les effets de cette commande, éventuellement illustré par un exemple; on peut ensuite rajouter un niveau d'explication plus détaillé avec une liste exhaustive de tous les problèmes que l'on peut rencontrer pour exécuter cette commande.
Pour le guidage d'utilisation, il faut exploiter la structuration en buts et sous-buts de la Représentation Conceptuelle puisqu'elle correspond à une logique d'utilisation selon les buts de l'utilisateur et qu'elle permet donc de répondre à des questions du type "comment faire pour...?".
De plus, ce guidage d'utilisation peut être personnalisé en utilisant une procédure effective propre à un utilisateur ainsi que la mémorisation des transactions déjà effectuées.
La Représentation Externe telle qu'elle sera vue par l'utilisateur est une composition des paramètres standard et des paramètres variables de l'application puisqu'à chaque moment d'une transaction, plusieurs options sont offertes à l'utilisateur; ces options provenant à la fois des commandes standard et des commandes spécifiques à l'application.
Pour illustrer ce fait, nous présentons ci-dessous un exemple d'écran utilisant un logiciel de multifenêtrage avec interruption d'opération.
L'opération "Indexer" a été interrompue (paramètre standard) de manière implicite par l'activation de l'opération "Consulter thesaurus" car le documentaliste voulait connaître les mots-clés reliés par une relation de hiérarchie au mot-clé "informatique" afin de mener à bien son opération d'indexation de document.