

Les mains se dessinent- Escher
Je suis plus sûr de mon jugement que de mes yeux... Denis Diderot
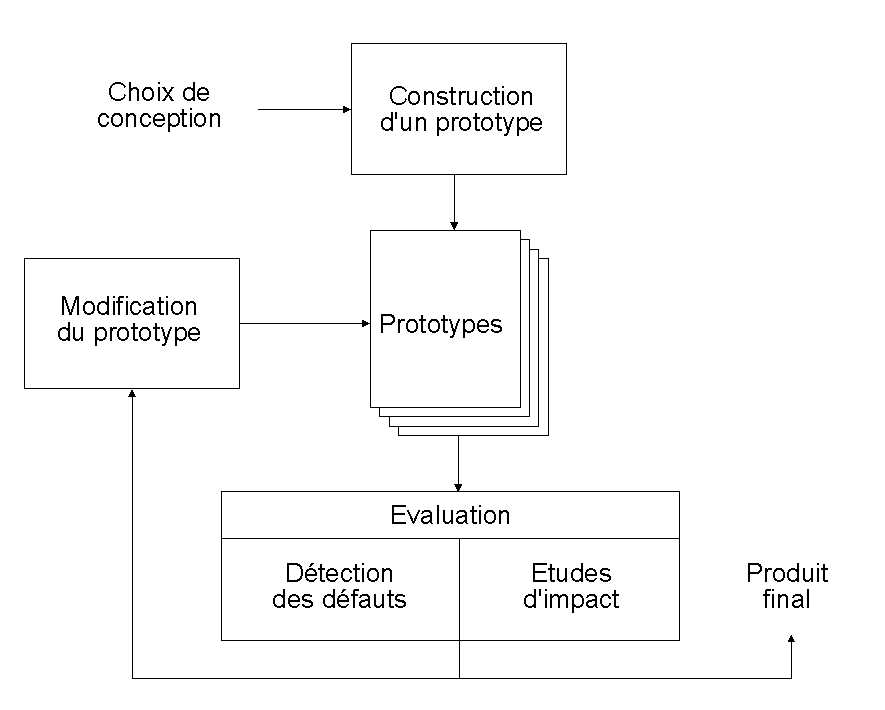
L'évaluation se fait à différents niveaux de la conception de l'interface. Idéalement, on devrait suivre les étapes suivantes:
Certaines de ces méthodes sont coûteuses: elles doivent être adaptées aux objectifs du produit réalisé. Dans notre cas, nous nous sommes heurté à la complexité de l'analyse, la lourdeur des protocoles expérimentaux, le choix des échantillons d'expérimentation et le temps de dépouillement des résultats.
Nous avons eu la possibilité d'assister et de participer au projet d'évaluation de la multimodalité par Sharon Oviatt [OVIA94]. Pour mener à bien ses expériences, elle a réalisé une manipulation du type magicien d'Oz (Figure 60).
Les sujets sont mis en présence d'un système, qu'ils croient réel, où la majorité des actions sont en fait effectuées par un "magicien" caché. On filme tous les faits et gestes, toutes les réactions du sujet pour les commenter et les analyser ensuite. Au cours de l'interaction, le magicien peut introduire aléatoirement des petites erreurs de dialogue afin de modérer l'enthousiasme du sujet. A la fin de l'expérience, une entrevue est menée par le responsable de l'expérimentation afin d'obtenir encore des indications de l'utilisateur ou de déterminer si celui-ci s'est aperçu de la supercherie, et à quel moment. L'analyse des résultats est alors faite, les vidéos dépouillées, découpées en sections pour en faire ressortir les éléments intéressants (Figure 61).
Les résultats seront fournis par Sharon Oviatt au cours de l'année 1995, nous pouvons toutefois dévoiler que les première constatations abondaient dans le sens des observations faites à l'ICP Grenoble ou au LIMSI: la multimodalité voix-stylo est dominante dans le dialogue. Les résultats à l'ICP et au LIMSI ont été obtenus sur des écrans tactiles, matériels proches des ordinateurs à stylo puisqu'ils permettent eux aussi la manipulation directe d'objets à l'écran.
De multiples expérimentations sont réalisées pour observer les sujets, sans forcément mettre en œuvre la technique coûteuse du Magicien d'Oz. Nous parlerons par exemple de l'expérience menée par Claudie Faure afin d'observer l'utilisation des interfaces faisant intervenir le stylo [FAUR95]. Un prototype, basé sur la première interface de TAPAGE, a été spécialement conçu pour cette évaluation. L'utilisateur, qui est filmé tout au long de l'expérience, se voit remettre des instructions décrivant la tâche et les interactions possibles. La tâche (déplacer des lignes) n'est pas le but pricipal de l'expérimentation, cependant le moyen d'y arriver a fourni des éléments très interessants quant au comportement des utilisateurs face à ce genre d'interface. Par exemple, même si le geste d'effacement n'est pas bien reconnu, le sujet va toujours persister dans l'utilisation de cette modalité alors qu'il a à sa disposition un menu pour effectuer cette action.
Nous avons envisagé plusieurs types d'évaluations. Certaines ont été menées jusqu'au bout, d'autres sont des propositions encore dans nos cartons que nous espérons pouvoir réaliser bientôt.
Deux protocoles ont été mis au point pour réaliser l'évaluation de TAPAGE. Une seule des deux expériences a été menées à son terme, la première.
Nous donnons ici le texte qui était remis à chaque sujet avant le début de l'expérience.
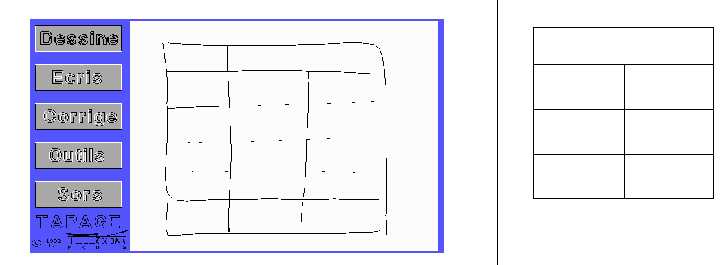
Dans le test qui va suivre, vous avez à votre disposition un ordinateur avec lequel on ne peut communiquer qu'à l'aide d'un stylo. Le travail qui vous est demandé, est de recopier les sept tableaux de la page suivante, sans toutefois avoir à les remplir. Pour effectuer cette opération vous pouvez vous déplacer dans les menus proposés par l'application (en "appuyant" sur les boutons avec le stylo) et en particulier, utiliser les fonctions "Dessine" pour dessiner ou ajouter des traits, "Efface" pour en supprimer un ou encore "Mets" pour en déplacer, ces deux dernières fonctions se trouvant dans le sous-menu "Corrige". Lorsque vous êtes dans le sous-menu "Dessine", vous avez la possibilité d'appuyer à tout moment sur le bouton "Idéalise" afin de voir comment l'ordinateur a compris votre dessin. Les actions de correction ("Mets", "Efface", etc...) impliquent une sélection des objets, vous avez donc à votre disposition les différents types de sélection suivant :
Pointages Sélection partielle Sélection multiple
Il faut remarquer que la sélection multiple est aussi possible par pointages successifs et que la désélection s'effectue par pointage. A cause des erreurs de parallaxe, un type de pointage étendu est disponible, il suffit de passer sur la ligne à sélectionner en faisant un petit trait.
Pour commencer un nouveau tableau, il suffit d'appuyer sur le bouton "Sors" du menu principal puis le bouton "Nouveau".
Pendant toute la durée de l'expérience, toutes vos paroles seront enregistrées. Nous vous demandons donc de dire ce que vous faîtes, pensez ou de décrire ce qu'il se passe sur votre écran durant la session de travail.
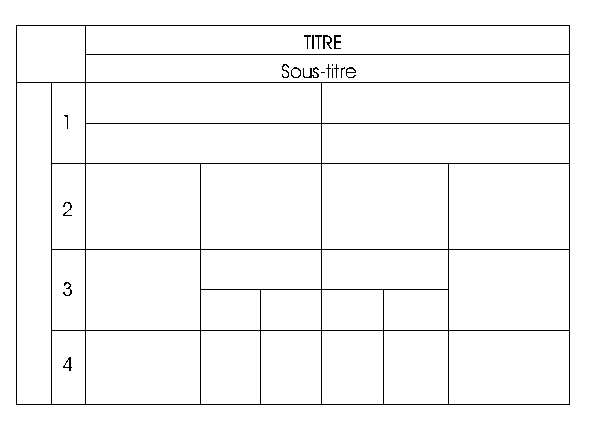
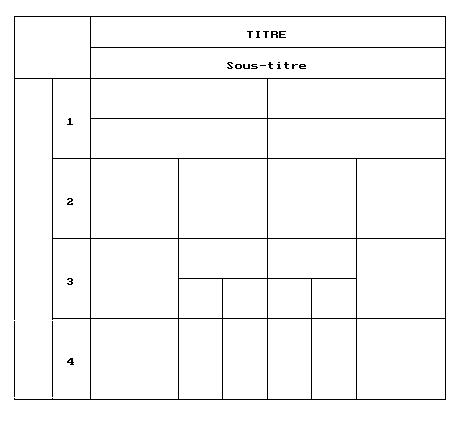
Voici les sept tableaux à recopier :
Tableau 1 Tableau 2 Tableau 3 Tableau 4 Tableau 5 Tableau 6 Tableau 7
Si l'évaluation des performances du logiciel doit être faite sur l'ensemble de celui-ci, on peut toutefois considérer chacun de ses modules pour y cerner les problèmes rencontrés lors d'une session normale de travail.
Des tests de fiabilité de la parole, avec détermination des taux de reconnaissance peuvent être menés. Nous aurions pu utiliser les résultats fournis par le constructeur de la carte, mais aucun pourcentage n'est disponible. En conséquence, nous proposons notre propre évaluation du reconnaisseur de parole en deux parties:
Prononciation de 5 ou 6 mots du vocabulaire de l'application en mots isolés par N individus. Ceci doit nous donner un pourcentage de réussite. Le problème est que le système utilisé est monolocuteur: il faut donc, avant chaque test, faire un apprentissage pour chaque sujet. Cet apprentissage peut être long (à peu près une heure pour un vocabulaire de plus de 60 mots comme celui de TAPAGE).
Prononciation de phrases entières dans lesquelles on trouve des commandes de TAPAGE. Pour cela, on récupère des phrases qui ont été prononcées lors des utilisations de TAPAGE et on demande juste au sujet de les lire. On extrait alors un pourcentage de reconnaissance des commandes de l'application. On profitera de l'apprentissage précédent; les sujets seront les mêmes que précédemment.
De ces tests, nous pourrons tirer un chiffre qui sera le reflet de la fiabilité du système de reconnaissance de la parole dans nos conditions d'utilisation. Toutefois, nous devrons considérer le biais introduit par le faible vocabulaire utilisé. Le problème étant celui des mots semblables, l'introduction de deux mots semblables dans le vocabulaire des 5 ou 6 mots pourrait sans doute réduire ce biais. Il faudrait, dans un premier temps, déterminer ces mots semblables en repérant ceux qui sont le plus souvent confondus.
Comme pour la parole, nous aurions dû bénéficier de pourcentages de réussite pour le reconnaisseur d'écriture. Ce n'est pourtant pas le cas et les seuls chiffres dont nous disposons paraîssent très fantaisistes (99% de succès annoncé dans la presse spécialisée). Nous proposons donc ces trois petits tests pour avoir une idée de la qualité de nos reconnaisseurs: pour chaque expérience nous mesurons le temps et le pourcentage de réussite:
Nous attendons de cette petite expérience des pourcentages nets de succès mais aussi de voir comment l'utilisateur est influencé par le retour et s'il perd beaucoup de temps dans les corrections ou à attendre les interprétations (entre chaque mot? chaque lettre?).
Enfin, afin de tester les modules propres à l'application, nous avons développé une version étendue de TAPAGE, qui est spécifiquement dédiée aux tests. Dans cette version, le module de remise en forme des tableaux fournit les résultats de chaque opération élémentaire le constituant. Cette progression pas à pas dans les entrailles de TAPAGE permet au superviseur de repérer les erreurs à leur source.
Nous décidons d'effectuer la même batterie de tests sur les trois types d'utilisateurs suivants :
Leur tâche consistera à réaliser les créations ou modifications concernant les trois tableaux suivants :
Les résultats de ces évaluations nous permettront certainement d'apporter de petites modifications au module de remise en forme (changement des seuils par exemple). Pour ce qui concerne la phase de correction, cette évaluation va nous permettre d'étudier le comportement des utilisateurs dans cette phase, de plus le superviseur extraira de l'expérience leurs desiderata.
Un petit test amusant est venu compléter cette évaluation. Nous avons demandé à 3 novices de créer la structure du plus simple des 7 tableaux demandés sur un tableur très populaire et très répandu sur le marché (Excel de Microsoft). Malgré la souplesse du logiciel, aucun n'a réussi à construire ce tableau... Citer [APTE93a].
Nous donnons donc les résultats de la première évaluation, portant sur la recopie de 7 tableaux à structures plus ou moins complexes. Nous avons réuni 7 utilisateurs (on trouvera en Annexes: X.3. Les détails de l'évaluation). Le module de reconnaissance de parole demandant un long apprentissage, nous avons préféré nous passer de cette fonctionnalité pour, dans un premier temps, tester préferentiellement le module de remise en forme et des éléments de l'interface : les retours visuels, les commandes gestuelles, l'utilisation des menus et les opérations de correction. En revanche, il a été demandé aux usagers de commenter leurs faits et gestes et les réactions de TAPAGE. Ceci afin de les enregistrer pour une étude ultérieure de la bande, mais aussi pour juger de la facilité pour un utilisateur à parler seul devant une machine pendant son travail. Pour chacun des tableaux, l'utilisateur était chronométré, dans chacune des phases de la conception incrémentale : production (dessin) et correction.
Les erreurs constatées dans les tableaux, amenant l'utilisateur à se servir du module correction, sont dues à la mauvaise recopie du tableau modèle par l'utilisateur, à la mauvaise qualité de la production : l'intention du dessinateur n'est pas clairement exprimée par le dessin, ou à des erreurs d'interprétation par le système. Lors de la création, les novices se servent beaucoup de l'option d'idéalisation qui leur est fournie afin de voir (pratiquement à chaque trait, s'ils le veulent) ce que l'ordinateur a compris. On constate que lorsque l'utilisateur est entraîné dans une spirale d'erreurs d'interprétation, ce qui arrive quand les traits sont trop proches par exemple, il finit par abandonner la conception du tableau pour recommencer totalement, pas forcément en utilisant la commande "nouveau", mais aussi en sélectionnant tous les traits et en les effaçant. Il commence alors son nouveau tableau en parlant de "stratégie" pour s'adapter aux comportements de l'outil. Lors de la correction, nous avons remarqué l'utilisation très personnelle de certaines fonctions : le "mets ça là" se voit par exemple décomposé en une sélection d'objet, la commande "mets" et le retraçage du trait à déplacer à l'endroit choisi. Ceci n'avait pas été prévu dans le protocole, mais le fait de retracer le trait fournit la position et l'effet voulu est obtenu. Lors de cette même correction, nous avons constaté de gros problèmes de parallaxe pour la sélection des traits. Certains utilisateurs ont envie de parler afin de parvenir plus rapidement au but, d'autres ne disent pas un mot malgré nos recommandations en début de session.
Nous donnons dans le tableau ci-dessous les grandes lignes des résultats obtenus :
Création Création Correction Correction Abandons
Min. Max. Min. Max.
Tableau 8" 25" 0" 25" 0
1
Tableau 12" 42" 0" 22" 0
2
Tableau 26" 1'08" 0" 30" 1
3
Tableau 20" 1'15" 0" 1'00" 2
4
Tableau 15" 1'00" 0" 1'00" 0
5
Tableau 22" 1'16" 0" 1'00" 1
6
Tableau 36" 1'59" 0" 3'25" 0
7
La longue correction constatée au tableau 7 provient d'une grosse erreur de structure du créateur du tableau dès le départ, la modification a été réussie après de longs moments de comparaisons entre le modèle papier et la version fournie par TAPAGE : il n'est pas facile de recopier un tableau (erreurs classiques des poteaux et des intervalles...). Hormis cette exception, le temps moyen de recopie d'un tableau se situe à moins d'une minute : 57" exactement sur l'ensemble des tests. Enfin, on constate que le module de correction n'a été utilisé qu'a 15 reprises.
Dans diverses autres petites expériences informelles et dans une ébauche de la seconde, voilà ce que nous avons constaté.
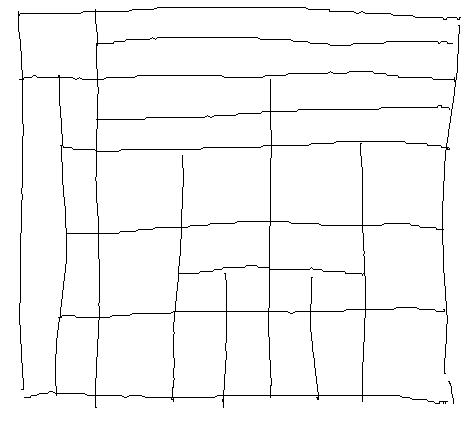
Nous présentons tout d'abord un exemple de tableau recopié, et rempli (Figures 62a et 62b) et un tableau créé à partir de sa description (Figures 63a et 63b).
En fonction des modules, nous constatons que les erreurs d'interprétation proviennent toujours du même type de comportement.
.
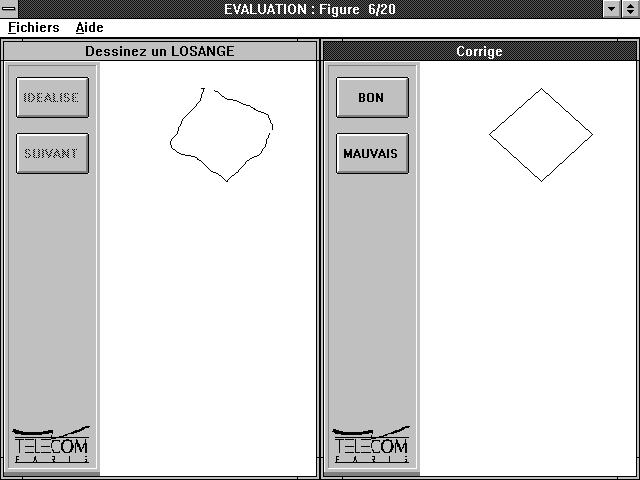
L'évaluation que nous avons mené dans le cadre du projet DERAPAGE ne vise pas à donner un résultat sur la multimodalité comme dans TAPAGE mais à quantifier la qualité de l 'algorithme de reconnaissance. Ainsi, nous avons créé un outil spécifique à cette évaluation: EVAL (Figure 64). Ce programme invite l'utilisateur à dessiner une figure choisie aléatoirement parmi les cinq présentes dans DERAPAGE (cercle, carré, rectangle, triangle ou losange) et ceci à 20 reprises. Ces figures sont choisies aléatoirement par EVAL. La distinction faite entre rectangle et carré nous permettra de quantifier la différence qu'impose l'utilisateur lors de la production de ces figures. Pour éviter les éléments pertubateurs de l'interface, la voix est utilisée par EVAL pour piloter l'interaction. Les instructions sont données à chaque étape d'une façon claire. A la fin de l'expérience, les résultats sont fournis par figure et globalement.
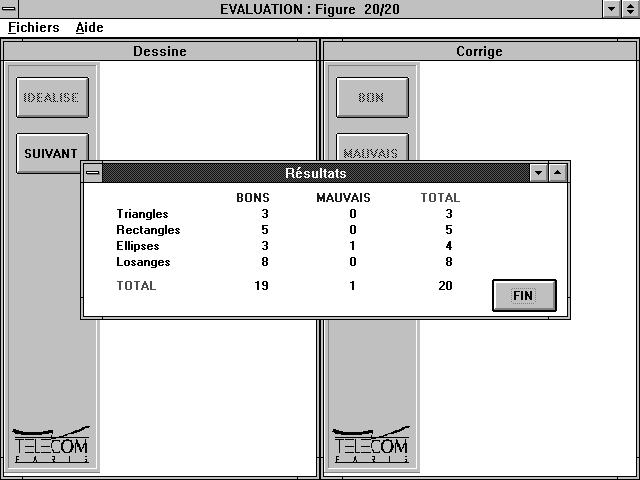
Pour chaque utilisateur, une fois les vingt figures dessinées, un tableau détaillé des résultats apparaît (Figure 65). En plus du taux global de reconnaissance, ce tableau donne le taux de succès pour chaque type de figure, ce qui permettra de focaliser les recherches sur une des figures s'il s'avère qu'un type est particulièrement défaillant.
Nous donnons ici les résultats en pourcentage obtenus par 20 utilisateurs à qui on avait demandé de considérer l'ordinateur à stylo comme une feuille de papier:
Rectangles Losanges Triangles Cercles TOTAL
1 100 100 85 100 95
2 100 100 100 100 100
3 100 33 66 75 75
4 100 66 100 100 95
5 83 100 70 100 80
6 100 100 100 100 100
7 66 100 20 100 75
8 100 100 100 100 100
9 100 100 62 100 84
10 100 85 100 66 85
11 80 100 100 90 90
12 100 80 100 75 90
13 71 100 66 100 85
14 100 75 66 100 85
15 100 66 85 75 85
16 100 100 100 100 100
17 100 100 100 100 100
18 100 66 100 100 95
19 100 25 66 66 70
20 100 66 100 100 95
TOTAL 95 83,1 84,3 92,4 89,2
Le taux global de reconnaissance est de près de 90%, ce qui, dans un système interactif en temps réel de ce type semble suffisant, l'utilisateur n'ayant que rarement plus de cinq ou six figures à réaliser. Nous utiliserons toutefois ces résultats pour tenter d'améliorer la reconnaissance des losanges et des triangles. Nous constatons que ce sont les figures comportant des diagonales qui posent problème.
Tous les types d'expériences sont bons pour faire avancer la recherche sur le comportement de l'homme face à la machine. Nous pensons toutefois que l'utilisation de maquettes, qui sont de « vrais systèmes », est une bonne chose, car ils permettent d'éviter des biais que l'expérience simulée peuvent engendrer à l'insu de l'expérimentateur.

|

|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}